わら山から「わら」を探す人工知能、「プレディクティブコーディング」とは?:5分で分かる最新キーワード解説(2/3 ページ)
不正行為の証拠発見を人間の数千倍のスピードで実行できる人工知能が登場した。訴訟大国の米国でビジネスを行う際には要チェックだ。
「プレディクティブコーディング」は何を行うのか?
図1に見るように、プレディクティブコーディングは企業のPCやサーバに蓄積された文書やメールデータなどから、請求された内容に関わるもの、例えば「◯◯製品の価格決定に関わるメールデータの全て」というような条件に当てはまるものを全部取り出し、重要性に従って整理する仕組みだ。
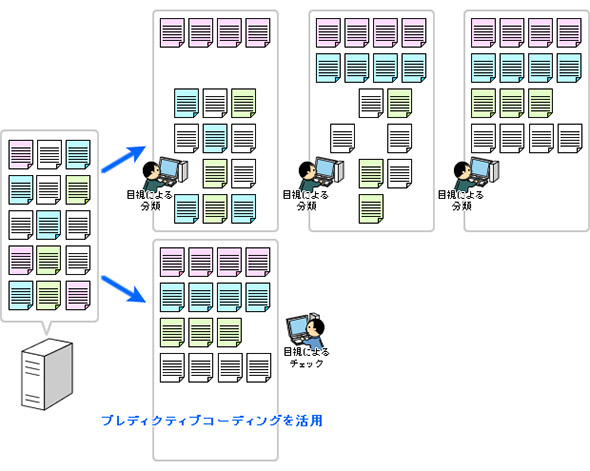
キーワード検索を行うツールは多々あるが、対象製品の価格決定に関わる内容と見なされるものかどうかの判断を行うものは少ない。プレディクティブコーディング技術を使えば、キーワードと文脈を判断し、条件に該当するかどうかを人工知能が精度高く仕分ける。そのスピードは人間の4000倍、精度は90%以上に及ぶ(UBICの事例)。1GBの不要情報の削減は、約7000〜1万ドキュメントのレビュー工数(数百時間相当)の削減に当たるといい、少しでも対象データを絞り込めれば大きなコストと期間の節約になる。
まるでわらの山の中から針を探すような(図1にのっとれば砂場から砂鉄を磁石で吸い上げるような)作業を自動化するイメージだ。しかし、プレディクティブコーディングが実際に行うのは、わらと針のように明らかな違いがひと目で分かるものをより分けることではない。わらの山のわら同士の違いを見分ける作業なのだ。
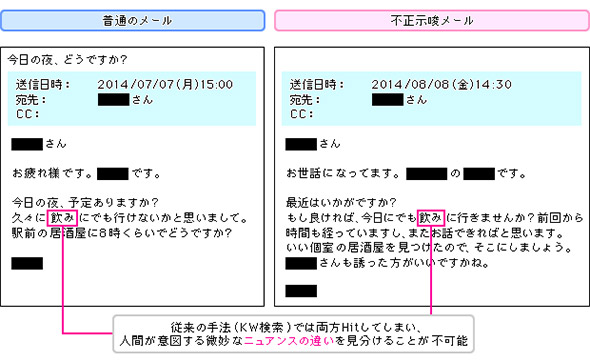
図2で示す2つのメール文面はよく似ている。「飲み」という言葉を含むメールをキーワード検索すると両方がヒットして、両者に区別は付けられない。しかし、プレディクティブコーディングによれば、右のように宛先や人名、その他の要素を含む単語が「飲み」という単語とともに文章中に表れる(共起)と、例えば価格カルテルの相談を持ちかけるメールである可能性があるとして、不正示唆メールであるというスコアを算出するのだ。
「伝達情報量」を利用したUBICの機械学習
このような仕分けは、不正調査や人間行動について深く勉強し、経験を積んだ専門家(例えば弁護士など)でなければ不可能だ。かつては、こうした推論を行うのに専門家の判断ルールをプログラム化して機械が学習し、専門家の代わりを務めるルールベースの推論エンジン(エキスパートシステム)が使われた。
しかし、ルールがあまりに大量で複雑になるため、広範な利用には至っていない。現在の人工知能研究は、ルールを定義するのではなく、データの特徴から評価軸を作り出し、コンピュータが自分で学習する機械学習の技術が追求される。
UBICは機械学習の手法の中でも「伝達情報量」による学習手法に着目した。これは「重要文書」と「文書中の概念」といった2つの要素の相互依存の度合いを表現する手法である。具体的な方法はこうだ。
まず、専門家(弁護士や調査士など)の手により、調査対象の中から少量の文書やデータをサンプル抽出して、調査対象として重要か否かを判定し、その結果を「教師データ」とする。次に、人工知能が教師データのテキストを形態素(意味をなす最小単位)に分解し、それぞれの形態素に、先ほどの共起関係も含めたさまざまな観点から重要度を評価して「重み付け」を行う。ここにUBIC独自の技術とノウハウが生かされる。
重み付けが終わると、そのデータは調査対象全体の評価軸として利用できる。後は、その他の調査対象に含まれる要素を重み付けに基づいてスコアリングすればよい。スコアリングは1回でなく、何度も繰り返し行うことで判定精度を高められる。
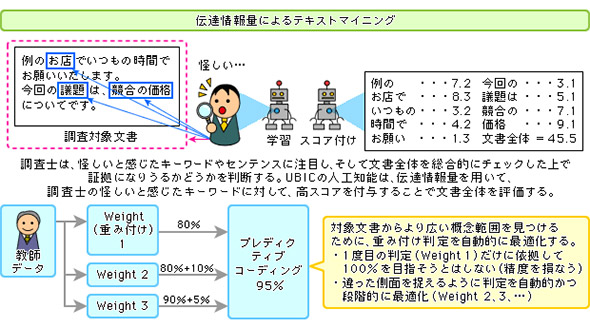
この過程を通して、目的と関連のない文書やデータは対象から外し、関連性=スコアが高いものから先に弁護士がレビューできるように整理する。結果として弁護士のレビュー対象が減り、また関連性が高い順にレビューできるため、効率もよくなる。
実績では、全体の55%程度のファイルを精査した時点で、その後重要な情報が出てこないようになるという。レビューが迅速化するだけでなく、属人的な判断のばらつきがなくなって精度も上がる。レビュー期間を短縮すれば、訴訟対応の戦略を練る時間をより長く確保できることになる。専門家の暗黙知を解明してルール化する必要がなく、暗黙知を暗黙知のまま自動的に判断基準とするこの仕組みは、計算量も小さくて済み、強力なコンピュータ性能は必要ない。
Copyright © ITmedia, Inc. All Rights Reserved.