どちらが大事? パーソナルデータ活用とプライバシー:セキュリティ強化塾(2/6 ページ)
年金情報漏えい事件を受け「パーソナルデータ」の保護体制に疑問の声。データ活用とプライバシー保護の折り合いをどうつけるべきか。
パーソナルデータはどこまで利活用できるのか?
2014年6月に決定された「パーソナルデータの利活用に関する制度改正大綱」ではパーソナルデータの利活用についての政府方針が示され、12月には「骨子案」ができ、個人情報保護法改正の法案が作られ、現在国会で審議中だ。
法律上の「個人情報」にあたる情報に法規制がかかるとしても、個人が他人に知られたくない情報は他にもあり、「個人情報」以外の情報の組み合わせで個人を特定できる場合もある。広い意味でのパーソナルデータの利活用について、プライバシーリスクを避ける対策をとる必要がある。
どのような情報なら個人が特定されるリスクがないと判断できるかは難しい問題だ。マイナンバーのように、絶対外部に漏らさないという保護の仕方をするならある意味簡単だが、第三者提供も含め利活用を図ろうとすると、どこまで匿名加工(個人とレコードの切り離し)をすれば大丈夫といえるかに明確な答えはない。
図2は米国の例だが、マサチューセッツ州が医療情報から氏名などを削除して公開したところ、その一部を投票者名簿(米国では公開情報)にある州知事の生年月日と性別、郵便番号の情報と照合されて医療情報が特定されてしまった。
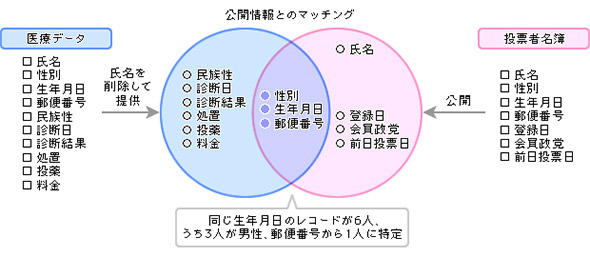
日本ではもちろん事情が違うが、似たようなことは必ず起きる。身近な例で言えば、氏名や住所の番地を削除した「自動車購入者リスト」があれば、購入した自動車が珍しいものなら町内の人はすぐに誰かを特定できよう。しかし「赤い洋服を買った人」「サイズはS」という情報だけなら、他の情報と照合しても個人特定の可能性は低いかもしれない。
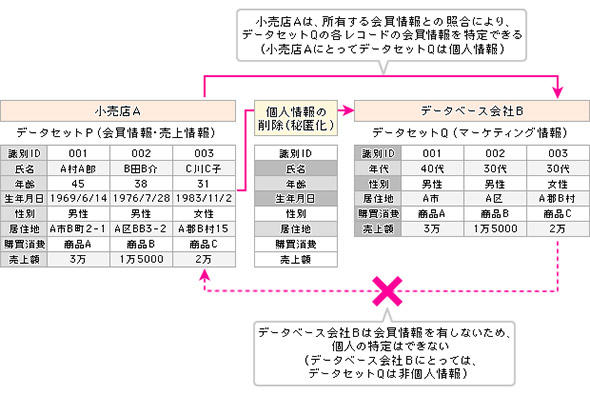
他の情報との照合で個人特定できる可能性の高さを「容易照合性」といい、改正個人情報保護法では図3のように識別IDが個人情報とひも付かないように「匿名化」すれば、容易照合性は低く、社内での利活用や第三者への提供(基本的には利用目的は任意)が可能だという考え方をとっている。情報を受け取る側では、他の情報との照合をせず、元の情報に戻すような操作もしないことを義務付ける。
改正個人情報保護法が施行されると、個人情報保護委員会という新設組織が匿名加工情報にしたパーソナルデータの利用ガイドラインを作成し、認定個人情報保護団体である業界団体がそれぞれのガイドラインを作成して、参加企業はそれにならうことになる。
そのガイドラインは、消費者が納得できるようなものにする必要が当然あり、消費者代表が策定に参画するのが望ましい。しかしそもそもサービスの理解度や、個人が一意に識別されることのリスク想定に大きな幅があり、そう簡単ではなさそうだ。個人情報保護委員会と認定個人情報保護団体のガイドラインに具体的な匿名加工法などの詳細な記述が行われるとはあまり期待できない。企業としては、自分自身で方策を講じ、責任ある運用ができる利活用と情報保護の枠組み構築に取り組む必要がある。
k-匿名化は有効か?
情報の匿名化の度合いを決める1つの考え方として、同じような属性の人がk人以上いる状態を示す「k-匿名性」がある。これは例えばk=10なら同じ属性をもつ対象者が10人以上いるという指標だ。これを手作業または自動処理で導き出すと、kの値が一定以下のデータを削除する「k-匿名化」ができる。
匿名性をさらに上げるためにはデータのランダム化を組み合わせる「Pk-匿名化」技術も開発されていて、匿名化の目安になると注目されている。しかし、企業ビジネスの現場に果たしてなじむかどうかは課題。例えば膨大なログデータを対象にk-匿名化を自動化するような仕組みが構築できればよいが、現時点では難しそうだ。
Copyright © ITmedia, Inc. All Rights Reserved.