ژ¸‚ء‚½گ؛‚ً‰¹گ؛چ‡گ¬‚إژو‚è–ك‚·پuƒ{ƒCƒXƒoƒ“ƒNپv‚ئ‚حپHپF5•ھ‚إ•ھ‚©‚éچإگVƒLپ[ƒڈپ[ƒh‰ًگàپi2/4 ƒyپ[ƒWپj
•a‹C‚إڈo‚·‚±‚ئ‚ھ“‚¢پu–{گl‚جگ؛پv‚ًژو‚è–ك‚·‰¹گ؛چ‡گ¬‹ZڈpŒ¤‹†ƒvƒچƒWƒFƒNƒgپuƒ{ƒCƒXƒoƒ“ƒNپv‚ھژn“®‚µ‚½پB‰¹گ؛چ‡گ¬‚جچإ‘Oگü‚ة”—‚éپB
‚±‚ê‚ـ‚إ‚ج‰¹گ؛چ‡گ¬‹Zڈp‚ج‰غ‘è‚حپH
پ@ƒ{ƒCƒXƒoƒ“ƒNƒvƒچƒWƒFƒNƒg‚ج”’[‚حپAژRٹفڈy‹³ژِ‚ھگi‚ك‚ؤ‚«‚½‰¹گ؛‚جگ”—“I‚ب•ھگح‚ئچ‡گ¬‚جŒ¤‹†‚¾پB‚»‚جڈذ‰î‚ج‘O‚ةپAڈ‚µ‰¹گ؛چ‡گ¬‚ج—ًژj‚ًگU‚è•ش‚肽‚¢پB
پ@1950”N‘م‚©‚çژn‚ـ‚ء‚½‰¹گ؛چ‡گ¬‚جŒ¤‹†‚حپAچإڈ‰‚ح‰¹‚ئ‰¹‚ئ‚ج‚آ‚ب‚ھ‚è‚جƒ‹پ[ƒ‹‚ً”Œ©‚µ‚ؤپA‚»‚جƒ‹پ[ƒ‹‚ةٹî‚أ‚¢‚ؤ‰¹‚ً‚آ‚ب‚°‚郋پ[ƒ‹ƒxپ[ƒX‚ج‰¹گ؛چ‡گ¬‚©‚çژn‚ـ‚ء‚½پB‚±‚ê‚حTV”ش‘g‚≉Œ|‚إپu‰F’ˆگl‚جگ؛پv‚âپuƒچƒ{ƒbƒg‚جگ؛پv‚ئ‚µ‚ؤٹٹŒm‚ب‚à‚ج‚ئ‚µ‚ؤ‰‰‚¶‚ç‚ê‚邱‚ئ‚ھ‚ ‚é‚ظ‚اپA•sژ©‘R‚إ‚¬‚±‚؟‚ب‚¢‚à‚ج‚¾‚ء‚½پB
پ@‚»‚ê‚ھچ،پA“dکb‚âƒJپ[ƒiƒr‚ج‰¹گ؛ˆؤ“à‚ب‚ا‚إ•·‚©‚ê‚é‚و‚¤‚بپA‚©‚ب‚èژ©‘R‚بگ؛‰¹‚إ—¬‚؟‚ه‚¤‚ب”‰¹‚ة‚ب‚ء‚½‚ج‚ة‚حپAIT‚ج”“W‚ة‚و‚èپA–c‘ه‚ب—ت‚ج‰¹گ؛ƒfپ[ƒ^‚ًژو‚舵‚¦‚é‚و‚¤‚ة‚ب‚ء‚½‚±‚ئ‚ھ”wŒi‚ة‚ ‚éپB
پ@‚±‚ê‚ç‚ج‰¹گ؛چ‡گ¬‚ة‚حپA“ء’è‚جگl‚ج‰¹گ؛‚ًک^‰¹‚µپA‚»‚±‚©‚ç’P‰¹‚خ‚©‚è‚إ‚ب‚’PŒê‚╶ڈح‚ب‚ا‚ًگط‚èڈo‚µ‚ؤپAƒeƒLƒXƒg‚ئ‘خ‰‚·‚é‚و‚¤‚ةƒfپ[ƒ^ƒxپ[ƒX‰»‚µ‚½پu‰¹گ؛ƒRپ[ƒpƒXپv‚ًچى‚èپA”گ؛‚³‚¹‚½‚¢ƒeƒLƒXƒg‚ةچ‡‚ي‚¹‚ؤ•K—v‚ب•”•ھ‚ً’ٹڈo‚µ‚ؤگع‘±‚·‚éپu”gŒ`گع‘±چ‡گ¬پv‹Zڈp‚ھژg‚ي‚ê‚éپB
پ@1980”N‘م‚ةگ¶‚ـ‚ꂽ‚±‚ج”gŒ`گع‘±‹Zڈp‚ھپAŒ»چف‚ج‰¹گ؛چ‡گ¬•پ‹y‚جŒ´“®—ح‚ة‚ب‚ء‚½پBپuڈ‰‰¹ƒ~ƒNپv‚ب‚ا‚جƒ{پ[ƒJƒچƒCƒh‚ھگl‹C‚ً”ژ‚µ‚ؤ‚¢‚é‚ھپA‚±‚ê‚à”gŒ`گع‘±چ‡گ¬‹Zڈp‚ج‰—p‚ج1—ل‚¾پB
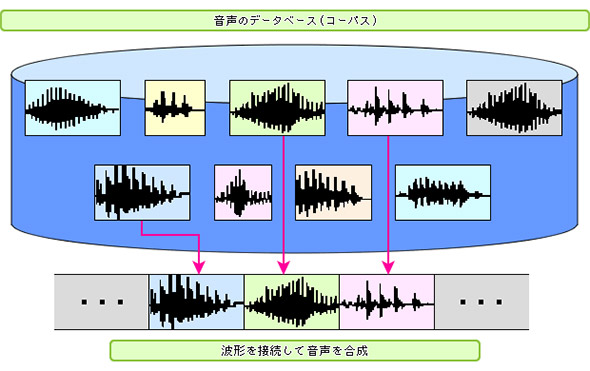
پ@‚µ‚©‚µپA‚±‚ج‹Zڈp‚ج‰غ‘è‚حپA‚ ‚éگl‚جگ؛‚ًچؤŒ»‚µ‚و‚¤‚ئژv‚¤‚ئپA‚»‚جگl‚جگ؛‚ً’·ژٹشƒXƒ^ƒWƒIک^‰¹‚·‚é•K—v‚ھ‚ ‚邱‚ئ‚¾پBژ©—R‚ةڈ‘‚©‚ꂽ•¶ڈح‚ً”گ؛‚³‚¹‚é‚ة‚حپA10ژٹش‚ً’´‚¦‚éک^‰¹ƒfپ[ƒ^‚ھ•K—v‚ة‚ب‚èپAƒXƒ^ƒWƒI‚إک^‰¹‚µپAŒمڈˆ—‚ً‰ء‚¦‚ؤƒfپ[ƒ^ƒxپ[ƒX‰»‚µ‚ؤژg‚¦‚é‚و‚¤‚ة‚ب‚é‚ـ‚إچإ’ل‚إ‚à100–œ‰~’ِ“xپAڈêچ‡‚ة‚و‚ء‚ؤ‚ح‚»‚ج10”{‚àƒRƒXƒg‚ھ‚©‚©‚é‚ئ‚à‚¢‚ي‚ê‚ؤ‚¢‚éپB
پ@‚»‚à‚»‚àŒ»چف”Œê‚ھچ¢“ï‚بٹ³ژز‚جŒ’ڈيژ‚جگ؛‚ً‚±‚ج‹Zڈp‚إچؤŒ»‚·‚é‚ج‚ة‚ح–³—‚ھ‚ ‚éپB‚ـ‚½پA‘هƒTƒCƒY‚جƒfپ[ƒ^ƒxپ[ƒX‚ًژg‚¤‚½‚كپA‰¹گ؛چ‡گ¬ڈˆ—‚ًƒ†پ[ƒUپ[‚جژ茳‚ج’[––‚إچs‚¤‚ة‚ح—e—تپAگ«”\“I‚ة‚à–â‘è‚ھ‚ ‚ء‚½پB
‰غ‘è‚ًچژ•‚µ‚½پuHMMپv‚ً—ک—p‚µ‚½‰¹گ؛چ‡گ¬‹Zڈp
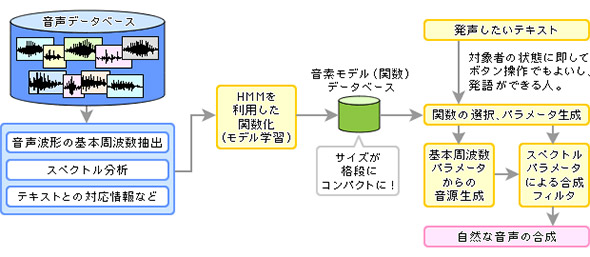
پ@‚±‚ج‰غ‘èچژ•‚ج“¹‚ًژ¦‚µ‚½‚ج‚ھپA1995”N‚ة–¼Œأ‰®چH‹ئ‘هٹw‚ج“؟“cŒbˆê‹³ژِ‚ھ’ٌˆؤ‚µ‚½پuHMMپiHidden Markov ModelپA‰B‚êƒ}ƒ‹ƒRƒtƒ‚ƒfƒ‹پjپv‚ً—ک—p‚µ‚½“Œv“I‰¹گ؛چ‡گ¬‹Zڈp‚¾پB
پ@‚±‚ê‚حپA“¯—l‚ةک^‰¹‚³‚ê‚ؤƒeƒLƒXƒg‚ئ‚جٹضکA•t‚¯‚ھ‚³‚ꂽƒfپ[ƒ^‚ً—ک—p‚·‚é‚ھپA‚»‚ê‚ً‚»‚ج‚ـ‚ـ‚إ‚ح‚ب‚پAپuٹî–{ژü”gگ”پiگ؛‘ر‚جگU“®‚ً”½‰fپAگ؛‘ر‚ھگ§Œن‚·‚éگ؛‚جچ‚‚³پAƒAƒNƒZƒ“ƒg‚ة‘ٹ“–پjپvپuƒXƒyƒNƒgƒ‹پiگ؛“¹‚ج‹¤گU‚·‚éژü”gگ”پA•ê‰¹‚âژq‰¹‚جٹe‰¹‚ة‘ٹ“–پjپvپuƒٹƒYƒ€پi”Œê‚جƒXƒsپ[ƒhپjپv‚ئ‚¢‚ء‚½—v‘f‚إٹضگ”‰»‚·‚é‰وٹْ“I‚ب•û–@‚¾‚ء‚½پB
پ@‰¹گ؛ƒfپ[ƒ^ƒxپ[ƒX‚ًگ¶‚جگ؛‚إ‚ح‚ب‚پAٹضگ”‰»‚³‚ꂽگ؛پi‰¹‹؟ƒ‚ƒfƒ‹پj‚ة’u‚«ٹ·‚¦‚邱‚ئ‚ة‚و‚èپAٹi’i‚ةƒfپ[ƒ^ƒTƒCƒY‚ھڈ¬‚³‚‚ب‚邾‚¯‚إ‚ب‚پAƒpƒ‰ƒپپ[ƒ^‚ً•د‚¦‚邾‚¯‚إ‚³‚ـ‚´‚ـ‚ب‰¹گ؛‚ًچى‚èڈo‚¹‚éپB•،گ”‚جگl‚جگ؛‚ًچ¬‚؛چ‡‚ي‚¹‚邱‚ئ‚à‚إ‚«‚ê‚خپA‚ا‚±‚ة‚à‚ب‚¢گ؛‚ًچى‚èڈo‚·‚±‚ئ‚à‰آ”\‚¾پB
پ@‚½‚‚³‚ٌ‚جگl‚جگ؛‚ً•½‹د‰»‚µ‚½پu•½‹دگ؛پv‚àچ‡گ¬‰آ”\‚ة‚ب‚éپB‚»‚µ‚ؤٹeچ‘‚â’nˆو‚جپu•½‹دگ؛پv‚ًچى‚ء‚ؤ‚¨‚¯‚خپA‚ظ‚ٌ‚جڈ‚µ‚ج–{گl‚جگ؛‚إƒpƒ‰ƒپپ[ƒ^‚ً’²گ®‚·‚邱‚ئ‚ة‚و‚èپA‚»‚جگl‚جگ؛‚ة‹ك‚¢گ؛گF‚ًچى‚èڈo‚¹‚éپiکbژز“K‰پj‚ج‚¾پBگ”•ھ’ِ“x‚ج–{گl‚جگ؛‚جƒTƒ“ƒvƒ‹‚ھ‚ ‚ê‚خپA‚©‚ب‚èگ³ٹm‚ب–{گl‚جگ؛‚ھڈo—ح‚إ‚«‚éپB
پ@‰¹گ؛چ‡گ¬Œ¤‹†‚جگ¢ٹE‚إ‚حپu‚ا‚ꂾ‚¯ژ©‘R‚ب‰¹گ؛‚ھڈo—ح‚إ‚«‚é‚©پv‚ً‘½گ”‚جگRچ¸ˆُ‚ھژہچغ‚ة•·‚¢‚ؤ•]‰؟‚·‚éگ¢ٹE“I‚ب‰¹گ؛چ‡گ¬‹Zڈp‚جƒٹƒXƒjƒ“ƒOƒeƒXƒg‚ھٹJچأ‚³‚ê‚é‚ھپAHMM‚ً—ک—p‚µ‚½‰¹گ؛چ‡گ¬‹Zڈp‚ح‚»‚ج‘ه‰ï‚إ—DڈG‚بگ¬گر‚ًژû‚ك‚½پB‚»‚جŒمگ¢ٹE‚ج‰¹گ؛چ‡گ¬Œ¤‹†‚ج—¬‚ê‚ھ•د‚ي‚èپAچ،‚إ‚حگ¢ٹE‚ة‘½‚‚جŒ¤‹†ژز‚ھگ¶‚ـ‚êپA‚½‚‚³‚ٌ‚جک_•¶‚ھ‘±پX‚ئ”•\‚³‚ê‚é‚و‚¤‚ة‚ب‚ء‚½پB
Copyright © ITmedia, Inc. All Rights Reserved.