”]‚إٹ´‚¶‚½ˆَڈغ‚ً•¶ژڑ‚ة‚·‚éپufMRI”]ڈî•ٌƒfƒRپ[ƒfƒBƒ“ƒOپv‚ئ‚حپHپF5•ھ‚إ•ھ‚©‚éچإگVƒLپ[ƒڈپ[ƒh‰ًگàپi3/4 ƒyپ[ƒWپj
”]‚ھٹ´‚¶‚½“à—e‚ًپA–{گlˆبٹO‚جگl‚ة‚à—‰ً‚إ‚«‚éŒ`‚إگ„’è‚إ‚«‚é‹ZڈpپufMRIپvپB–²‚جŒ¾Œê‰»‚³‚¦‰آ”\‚ة‚ب‚é‚ئ‚¢‚¤ژd‘g‚ف‚ئ‚حپH
”]ڈî•ٌ‚ح‚ا‚¤ƒfƒRپ[ƒh‚³‚ê‚é‚ج‚©پH
پ@‚إ‚حپAfMRI‚إ‘¨‚¦‚½”]“à‚جŒŒ—¬•د‰»‚©‚çپA‚ا‚ج‚و‚¤‚ة’mٹo“à—e‚ھ‰ً“اپiƒfƒRپ[ƒhپj‚³‚ê‚é‚ج‚¾‚낤‚©پB
fMRI‚إ‚جŒv‘ھ‚ئƒVپ[ƒ“‹Lڈq
پ@چ،‰ٌ”•\‚³‚ꂽژہŒ±‚إ‚حپA‚ـ‚¸MRI‘•’u“à‚إ”يŒ±ژزپiگ¼“cژپ‚ç‚جک_•¶ژ·•Mژ‚ة‚ح6گlپB‚»‚جŒم‘‚¦‚ؤ‚¢‚éپj‚ةCM‚ب‚ا‚ج‰f‘œ‚ً–ٌ2ژٹشژ‹’®‚µ‚ؤ‚à‚ç‚¢پA”]ٹˆ“®‚ًfMRI‚إŒv‘ھ‚µ‚½پB‚»‚جˆê•û‚إپA“¯‚¶‰f‘œ‚ًڈم‹L”يŒ±ژزˆبٹO‚جگlپX‚ةژ‹’®‚µ‚ؤ‚à‚ç‚¢پAٹeƒVپ[ƒ“‚جگà–¾‚ئژَ‚¯‚½ˆَڈغ‚ً•¶ڈح‚ة‚µ‚ؤ‚à‚ç‚ء‚½پB‚±‚ê‚إپu”]ٹˆ“®‚ج‹Lک^پv‚ئپuƒVپ[ƒ“‹Lڈq•¶ڈحپv‚ج2’ت‚è‚جƒfپ[ƒ^‚ھڈo—ˆڈم‚ھ‚ء‚½پB
1–œŒآ‚ج’PŒê‚ً100Œآ‚ج“ء’¥‚ة‚و‚èپuŒ¾Œê“ء’¥‹َٹشپv‚ةƒ}ƒbƒsƒ“ƒO
پ@‚±‚ê‚ةگو—§‚؟پAŒ¤‹†ƒ`پ[ƒ€‚حGoogle‚ھٹJ”‚µ‚½پuword2vecپv‚ئ‚¢‚¤‹Zڈp‚ً—ک—p‚µپAWikipedia‚ج‘ه‹K–حƒeƒLƒXƒgƒfپ[ƒ^‚©‚çپu100ژںŒ³‚ج“ء’¥ƒxƒNƒ^پ[‚ً‚à‚آŒ¾Œê“ء’¥‹َٹشپv‚ًٹwڈK‚³‚¹‚ؤ‚¢‚½پB‚±‚ê‚ح’PŒêڈoŒ»•p“x‚â‘ٹٹض‚ب‚ا‚ج“Œv‚©‚瓱‚©‚ê‚é’PŒê‚ئ’PŒê‚ئ‚جˆس–،‚ج‹ك‚³‚ًپA100ژںŒ³‚ج‹َٹش“à‚إ‚ج“_‚ئ“_‚ج‹——£‚إ•\Œ»‚إ‚«‚é‚و‚¤‚ة‚·‚邽‚ك‚¾پiگ}3ژQڈئپjپB
پ@‚آ‚ـ‚èپAپu”Lپv‚ئپuŒ¢پvپAپu’jپv‚ئپuڈ—پv‚ب‚ا‚جˆê”ت–¼ژŒ‚إ‹¤’ت‚ج“ء’¥‚ً‘½‚ژ‚آ’PŒê“¯ژm‚âپAپuڈZ‚قپvپuŒڑ•¨پv‚ئ‚¢‚ء‚½چ‡‚ي‚¹‚ؤژg‚ي‚ê‚邱‚ئ‚ھ‘½‚¢ˆê”ت–¼ژŒ‚ئ“®ژŒ‚ح‹َٹش“à‚ج‹ك‚¢“_‚ئ‚µ‚ؤ•\Œ»‚³‚êپA‚³‚ç‚ةپu‚©‚ي‚¢‚¢پvپu‘¬‚¢پv‚ب‚ا‚ج–¼ژŒ‚â“®ژŒ‚ًڈCڈü‚·‚éŒ`—eژŒ‚à“Œv“I‚ة“¯ژ‚ةژg‚ي‚ê‚é•p“x‚ھچ‚‚¢–¼ژŒ‚â“®ژŒ‚ة‹ك‚¢‚ئ‚±‚ë‚ةˆت’u‚·‚é“_‚ئ‚µ‚ؤ•\‚³‚ê‚éپB
پ@‚ ‚ـ‚èˆêڈڈ‚ةژg‚ي‚ê‚ب‚¢’PŒê“¯ژm‚ح‰“‚—£‚ê‚邱‚ئ‚ة‚ب‚éپB‚»‚ج‰“‹كچ·‚ً•]‰؟‚·‚é’PŒê‚ج“ء’¥‚جگ”‚ھپu“ء’¥ژںŒ³پv‚إ‚ ‚èپA“ء’¥‚جگ”‚ھ100Œآ‚إ‚ ‚ê‚خپA’PŒê‚ج“ء’¥‚ح100ژںŒ³‚جپu“ء’¥ƒxƒNƒ^پ[پv‚ئ‚µ‚ؤ•\‚³‚ê‚éپB“ء’¥ژںŒ³‚ھ‘½‚¢‚ظ‚اڈعچׂب’PŒê‚ج“ء’¥‚ھŒ¾Œê“ء’¥‹َٹش‚إ•\Œ»‚إ‚«‚é‚ھپA‘½‚·‚¬‚é‚ئŒ¾Œê“ء’¥‹َٹش‚جٹwڈK‚ھ“‚‚ب‚éپi‚±‚ê‚ح‹@ٹBٹwڈK‚جٹî–{•”•ھ‚¾پjپB‚±‚±‚إ‚ح1–œŒê‚ج’PŒê‚ج‚»‚ꂼ‚ê‚ج“ء’¥‚ً100ژںŒ³‚ج“ء’¥ƒxƒNƒ^پ[‚ئ‚µ‚ؤٹwڈK‚µپA’PŒê‚ئ’PŒê‚جٹضکAگ«‚ً•\‚·پuŒ¾Œê“ء’¥‹َٹشپv‚ًچى‚èڈo‚µ‚½‚ي‚¯‚¾پB‰½‚©‚ج’PŒê‚حپA‚±‚ج‹َٹش‚ج’†‚ج‚ا‚±‚©‚ج1“_‚ة‚ ‚½‚邱‚ئ‚ة‚ب‚éپB
’PŒê‚جپu“ء’¥ƒxƒNƒ^پ[پv‚ئ”]ٹˆ“®‚ج‘خ‰‚أ‚¯‚ًژg‚ء‚ؤپAگV‚½‚ب”]ٹˆ“®‚©‚ç’PŒê‚ً—p‚¢‚ؤ’mٹo“à—e‚ًگ„’è
پ@’mٹo‚âˆَڈغ‚حٹ´‚¶‚½ژ“_‚إŒ¾Œê‰»‚³‚ê‚é‚ي‚¯‚إ‚ح‚ب‚¢‚ھپA’PŒê‚ئŒ‹‚ر‚آ‚¢‚½ˆس–،‚جڈî•ٌ‚ًژ‚ء‚ؤ‚¢‚éپB‚آ‚ـ‚èپA‚»‚ج‚و‚¤‚ب’mٹo‚âˆَڈغ‚ً•\Œ»‚·‚é”]ٹˆ“®‚حپA’PŒê‚جˆس–،‚ئٹضŒWگ«‚ً‚à‚؟پA”]ٹˆ“®‚ھ•\Œ»‚·‚éڈî•ٌ‚ح’PŒê‚ئ‚µ‚ؤ‰آژ‹‰»‚إ‚«‚é‚ح‚¸‚¾‚ئ‚¢‚¤‚ج‚ھ‚±‚جŒ¤‹†‚ج‘O’ٌ‚¾پB
پ@‚»‚±‚إژہŒ±‚إ‚حپA–ٌ2ژٹش•ھ‹Lک^‚µ‚ؤ‚ ‚é”يŒ±ژز‚ج”]ٹˆ“®ƒfپ[ƒ^‚ئپA‘¼‚جگlپX‚جپuƒVپ[ƒ“‹Lڈqپv•¶ڈح‚©‚ç’ٹڈo‚µ‚½’PŒê‚ج“ء’¥ƒxƒNƒ^پ[‚ئ‚ج‘خ‰ٹضŒW‚ًŒ©‚¢‚¾‚·‚ׂپA‹@ٹBٹwڈK‹Zڈp‚ًٹˆ—p‚µ‚ؤژو‚è‘g‚ٌ‚¾پB‚»‚جŒ‹‰تپA”]ٹˆ“®‚ئ’PŒê‚جٹe“ء’¥‚ئ‚ج‘خ‰ٹضŒW‚ً•\‚·پuڈd‚فŒWگ”پvپi‘خ‰ٹضŒW‚ھ‹‚¯‚ê‚خڈd‚پAژم‚¯‚ê‚خŒy‚‚ب‚éŒWگ”پj‚ً“±‚¢‚½پB
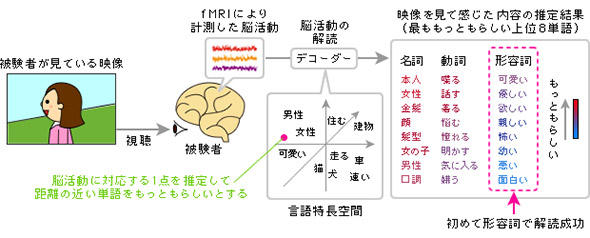
پ@گV‚½‚ةŒv‘ھ‚µ‚½”]ٹˆ“®‚ة‚»‚جڈd‚فŒWگ”‚ً“K—p‚µ‚ؤ“ء’¥ƒxƒNƒ^پ[‚ًژZڈo‚µپA‚»‚ꂼ‚ê‚ج’PŒê‚ج“ء’¥ƒxƒNƒ^پ[‚ئ‚ج‰“‹كچ·‚©‚çپu‚ ‚é”]ٹˆ“®‚ئٹضکAگ«‚ج‚ ‚é’PŒêپv‚ًƒXƒRƒAƒٹƒ“ƒO‚·‚邱‚ئ‚ةگ¬Œ÷‚µ‚½پBˆê”شƒXƒRƒA‚ھچ‚‚¢’PŒê‚ھپA‚»‚جژ‚ج‚»‚جگl‚ج’mٹo“à—e‚ً•\‚·’PŒê‚ئگ„’肳‚ê‚é‚ي‚¯‚¾پB‚½‚‚³‚ٌ‚ج”]ٹˆ“®‚ة‚آ‚¢‚ؤپA’PŒê‚ج‘خ‰‚ھ•ھ‚©‚ê‚خپAگ„’è‚ئ‚ح‚¢‚¦پu”]ٹˆ“®‚ج‰ً“اپv‚ھ‚إ‚«‚½‚±‚ئ‚ة‚ب‚éپB‚±‚ê‚ھپAگ¼“cژپ‚ç‚جپufMRI”]ڈî•ٌƒfƒRپ[ƒfƒBƒ“ƒOپv‚ج‚ ‚ç‚ـ‚µ‚¾پB
![fMRI”]ڈî•ٌƒfƒRپ[ƒfƒBƒ“ƒO‚ج•û–@‚جٹT”Oگ}](https://image.itmedia.co.jp/kn/articles/1712/20/mi2374_30009886_5min_003_MASK.jpg)
پ@‚±‚ج‚و‚¤‚ة‚µ‚ؤڈo—ˆڈم‚ھ‚ء‚½پu”]ڈî•ٌƒfƒRپ[ƒ_پ[پv‚ًژg‚¢پACM‰f‘œ‚ب‚ا‚ج‚ة‘خ‚·‚é”F’m“à—e‚ًپAƒVپ[ƒ“‚²‚ئ‚ةپAڈ]—ˆ‚حگ„’è‚إ‚«‚ب‚©‚ء‚½ˆَڈغ‚ـ‚إ‚àٹـ‚ك‚ؤپA’PŒê‚ئ‚µ‚ؤژو‚èڈo‚µ‚½‚ج‚ھچ،‰ٌ‚جژہŒ±‚جƒ|ƒCƒ“ƒg‚إ‚ ‚éپiگ}4پjپB
Copyright © ITmedia, Inc. All Rights Reserved.