自分でデータを集めて最適化を実現する「自己競争AI」とは?:5分で分かる最新キーワード解説(2/3 ページ)
サプライチェーンの「発注課題」に着目した、自己競争により学習を行うビジネス向けAI技術「自己競争AI」が登場した。
「自己競争AI」の仕組み
では「自己競争AI」はどのような学習を行っているのだろうか。研究チームは学習方法の中でも実績データが少ない中でデータを生成しながら試行錯誤を繰り返して、最適な結果を探りだす「強化学習」の手法を選んだ。
その対象にしたのがビールゲームである。ゲームプレイヤーを置き換えるために、自動受発注を行うディープラーニングベースの「AIエージェント」(強化学習エージェント)を作成、サプライチェーンの各拠点に見立てて互いに接続して全体のアウトカム(全体コスト)を観測できるようにした。各AIエージェント(各拠点)は自分以外のエージェントの在庫量や発注状況を知ることはできず、ただ自分の在庫状況や発注状況だけが把握できる。
4つのAIエージェントが1チームとなり、全体アウトカムが最小になるような最適状態を求めて試行錯誤を繰り返す。複数のチームにおいて全体アウトカムを競わせ、よい結果を出したチームを残し、効率のよくないチームは削除していく。
その結果、世代を経るうちに、よいアウトカムが得られるチーム(=AIエージェント群)だけが残るというのが基本的な仕組みである。もちろん同じ入力に対して各エージェントが同じ出力を出すようではいけないので、パラメータには乱数を加え、ランダムな出力を実現した。人間の「思惑」による発注のさじ加減(成功も失敗も含め)を乱数で再現した形である。まるで生物の遺伝子変異による進化を再現しているようだ。
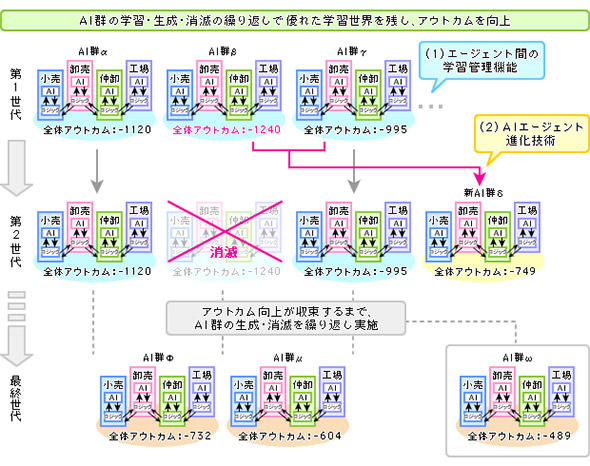
しかし、ただそれだけでは発注パターンの偏りが避けられず、学習速度も上がらないため、研究チームは「AIエージェント間の学習管理機能(図3の(1))」と「AIエージェント進化技術(図3の(2))を付け加えた。
学習管理機能
問題の1つは、サプライチェーンの構造に由来する潜在的な遅延と、各拠点の思惑=戦略に由来する遅延との見分けがつかないことだが、これについては、最初は少数のAIエージェントによる学習を行い、サプライチェーン構造上の遅延の程度を、各AIエージェントが学習したところでAIエージェントを増やす方法をとった。
すると、チーム内の各AIエージェント間で損益が互いにバランスするように調整(AIエージェントの協調)するようになる。これによりランダムな試行が互いに影響して学習停滞を起こすことを避けることができたという。
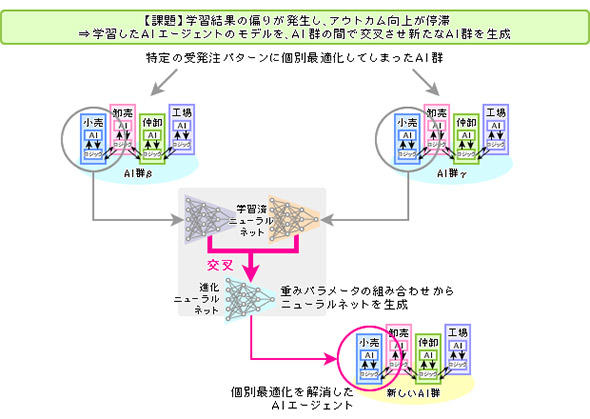
AIエージェント進化技術
一定の間隔で「突然変異」を引き起こすことで、AIの進化を図るのがこの技術だ。AIエージェントのモデルのパラメータ(重み係数やバイアスなど)を遺伝子に見立て、特定の演算式でミックスさせる突然変異を加えることで、学習パフォーマンスが一段と加速したという。「進化的計算アルゴリズム」を、こうしたAI群からなるシステムに応用したのが同社独自のアプローチである。
これにより、特定の受発注パターンに個別最適化して全体のアウトカムが上がらなくなる現象を避け、より総合スコアを短時間に向上させることができた。望ましくない突然変異も起きるが、スコアのよくないAIエージェントは淘汰される仕組みだ。
このような仕組みを通して、膨大な発注パターンの試行錯誤により、需要変動が起きてもそれを吸収できる最適な発注手法を発見していくのが、今回の「自己競争AI」開発の目的。上述のようにサプライチェーンの総コストを約4分の1にまで圧縮する効果が検証できたわけだが、学習に要した時間だけで言えば、一般的なディープラーニング開発環境において数時間で終了できたという。想定するサプライチェーンの複雑さにもよるが、かなり短時間での学習が可能な手法と言えそうだ。
ここで紹介したような「相手の状況が分からない中での意思決定」や「他に出し抜かれない戦略によりかえって損をしかねないジレンマ」は、サプライチェーンのみならず、ビジネスのあらゆる領域での課題でもある。今後、分野横断的に異業種企業が情報を仲立ちに連携していく社会において、ビジネスパフォーマンスを効率的にシミュレーションできる「自己競争AI」のような研究は、ますます重みを増すに違いない。現在は教科書的なビジネスモデルでの研究にとどまっているが、日立などの巨大グループで本格的な応用が行われれば、ビジネスの構造までも最適化するような影響力を持つのではないかと筆者は考える。
Copyright © ITmedia, Inc. All Rights Reserved.