ビッグデータの「その先」にあるデータ仮想化ソリューションって何だ?【前編】:IT導入完全ガイド(2/3 ページ)
データ仮想化ソリューションが求められる背景とその仕組みを基礎から解説する。
リアルタイムでの論理統合を実現
こうして生まれたデータ仮想化ソリューションは、データウェアハウスや各種業務システムのデータ、さらには各部門や個人が所有するExcelデータなどの各種データソースに対し、名寄せやクレンジングを含めた高度な統合処理をリアルタイムに施した上で、BIツールやExcel、Webアプリなどの外部アプリケーションへとデータを提供するというものだ。
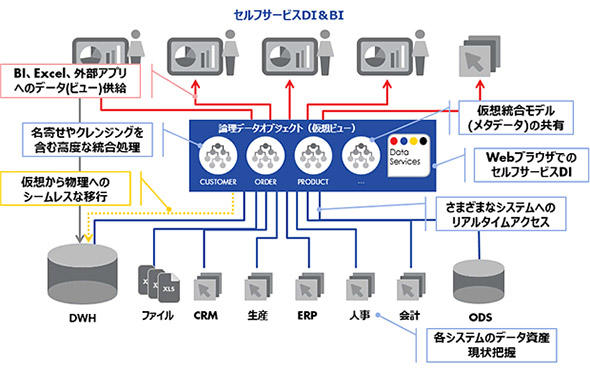
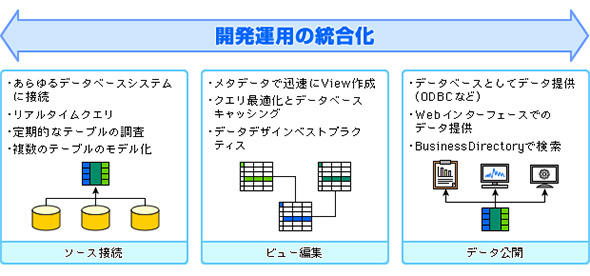
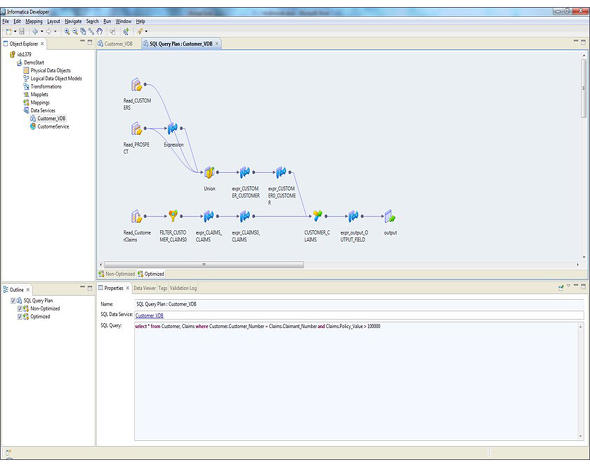
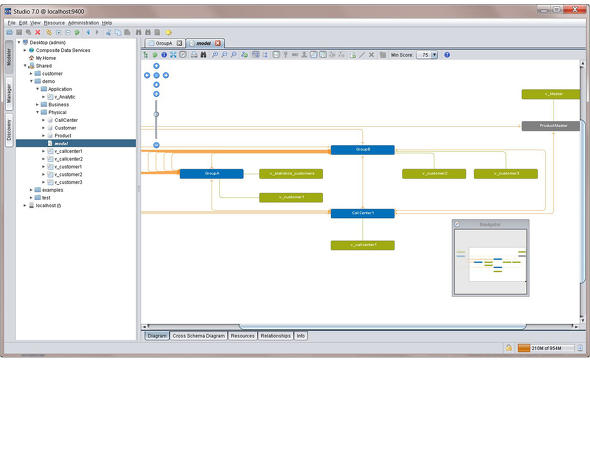
具体的には、さまざまな種類のデータベースシステムに接続し、テーブルのデータそのものを全て参照して、中のカラムごとに共通に引っぱれるようなものをリストアップしてモデル化を行う。ここでGUIなどを用いてビュー編集を行い、データのテーブルの決まりなどを作成する。この際、検索を行うとこのようなデータセットがあるとデータの系統図を含めて視覚的に表示してくれるようなソリューションもある。そしてWebインタフェースなどによりデータを公開するのである。
フロントエンド側から見るとデータはすぐ先にあるように見えるが、これは間にあるデータ仮想化ソリューションが、定義に従ってリアルタイムに各ソースへとデータを取りに行き、それぞれのデータの構成の違いについて整合性をとりながら組み合わせて返しているからである。ただし、同時に多くのリクエストが生じると処理が膨大になるので、各システムのデータのリアルタイムキャッシュを設けているようなデータ仮想化ソリューションもある。
また、もともとETLツールのベンダーが開発・提供するデータ仮想化ソリューションには、データを統合するためのロジックを、WebGUIで標準の部品を組み合わせるだけというノンコーディングで行えるものもある。ノンコーディングであれば、開発生産性はより高まることが期待される。こうしたソリューションの場合、誰かが作成した統合ロジックを、他の者がそのまま流用することも容易に行うことが可能だ。こうしてロジックの再利用を進めることで、データが企業の共有財産としてより一層、定着していくのである。
Copyright © ITmedia, Inc. All Rights Reserved.