まるで聖徳太子の耳のように複数話者を聞き分ける「分離集音」技術とは?:5分で分かる最新キーワード解説(1/4 ページ)
拾った音をリアルタイムに話者ごとに分離する「分離集音」技術が登場した。10人の訴えを聞き分けたという現代版、聖徳太子が降臨するか。
今回のテーマはマイクで拾った複数の人の声を、リアルタイムに話者ごとに分離する「分離集音技術」だ。例えば会議室に集まった人たちが同時に発話しても、「Aさんの話」と「Bさんの話」がきれいに分離されて記録できるようになる。これを音声認識と組み合わせれば議事録作成が効率化し、機械翻訳の精度も上がるというわけだ。一度に10人の訴えを聞き分けたという聖徳太子の耳もかくやあらんと思わせるこの技術、一体どんな仕組みなのか。
「分離集音技術」って何?
複数の人が同時に話しても、1人1人の音声を聞き分けられる技術。国立情報学研究所(NII)の小野順貴准教授と東芝が2011年4月〜2015年3月の共同研究で開発した技術を利用し、東芝が2016年10月に小型マイクアレイとタブレット(Atomプロセッサ)の演算能力を利用した試作機を開発して公表した。

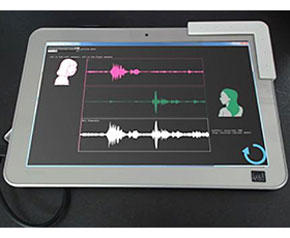
私たちは特に意識せずに騒音の中でも対面している人の声を明瞭に聞き分けることができる。しかし話す相手が複数で、同時に話しかけられると、少なくとも一方の話は十分に聞き分けられないのが普通だ。
機械ではもっとうまくいかない。そもそも聞きたい音声と、それ以外の音声、騒音、雑音を識別することが難しい。1人1人が専用のマイクを使い、騒音の少ない環境で録音するような場合、あるいは話者の位置を厳密に固定して、高指向性マイクを話者ごとに用意できる場合なら問題ないが、そんな条件が整えられるシーンは極めて限られる。
一方、会話から話者それぞれの鮮明な音声を取り出すことは、さまざまな業務やサービスの効率化、自動化のために重要だ。特に東京五輪開催を控える今、海外からのビジターを迎える際の対面サービスに、機械翻訳技術の精度向上が求められている。
自然言語処理の精度が近年著しく上がっており、その成果はスマートフォン搭載の音声サービスなどで私たちの身近でも感じられるようになった。しかしこの技術の弱点は、そもそもの音声に雑音が混じるなど、品質が落ちるとたちまち精度が悪化することだ。
スマートフォンのマイクなら、話者の口元近くで音声が拾えて、しかも話者は1人だけと決まっているからその弱点はカバーできるのだが、例えば会議の場面や、窓口での対面サービスの場面での利用を考えてみよう。マイクは対象とする話者の音声だけでなく、部屋の中に響く会話の反響音、周りの無関係の人たちの会話、会話以外の騒音なども全部拾ってしまう。その中から、目的の人の声を取り出すだけでも難しいが、対象とする人が複数で、それぞれの音声を別々に記録したいとなると、さらに難しくなる。
そこで注目されるのが「分離集音技術」である。これはテーブルの上に置いた(フリーハンドの)マイク(実際には複数マイクを搭載したマイクアレイ)を使い、さまざまな環境音のもとでも対象とする複数話者の音声を鮮明に分離するものだ。
これは機械翻訳だけでなく、例えば会議の議事録作成の効率化、音声情報からのマーケティング関連情報の収集、窓口業務での対応状況の正確な把握/データ化にも利用可能な技術である。こうした業務/サービスは録音スタジオのような管理された音響環境ではまず行われない。一般的なオフィスの会議室、オープンな打ち合わせスペース、多数の人が往来する対面カウンターなどでの業務が主な対象シーンとなる。
2016年の発表のポイントは、簡単に持ち運びできる低価格なタブレットとマイクアレイを用いて、ごくありふれた環境条件の中でも、リアルタイムに音声を話者ごとに鮮明に分離することができることを実機で実証したところにある。
Copyright © ITmedia, Inc. All Rights Reserved.