まるで聖徳太子の耳のように複数話者を聞き分ける「分離集音」技術とは?:5分で分かる最新キーワード解説(2/4 ページ)
拾った音をリアルタイムに話者ごとに分離する「分離集音」技術が登場した。10人の訴えを聞き分けたという現代版、聖徳太子が降臨するか。
会議室での複数の人の同時発話を明瞭に分離、再生
東芝の会議室で、実機でのデモを見た。会議に複数の人が参加している設定で、テーブルを前に数十センチの間を空けて横に座った2人に同時に発話してもらい、図2に示すマイクアレイを装着したタブレットで録音した。
この同時発話は、直接耳で聞いた状態でも、それぞれ何を言っているのか、推測はできるが完全には聞き取れなかった。しかし、発話直後にデモ用のプログラムで再生すると、右側の人の声だけが明瞭に再生された。次に発話者データを切り替える操作をして再生すると、今度は左側の人の声だけが、やはりくっきりと再生された。
タブレットは両者から50センチほど離れた前方に置いてあり、小型マイクアレイ(複数のMEMSマイクが1.6センチ間隔で並んでいる)はタブレットの角に装着してある。マイクは無指向性で、会議室内の音響は全部拾っている。マイクの指向性によって音声を分離しているのではないことは明らかだ。
2人の声はどうやって分離されたのだろうか。これには録音後に2段階の計算処理が行われている(図3)。
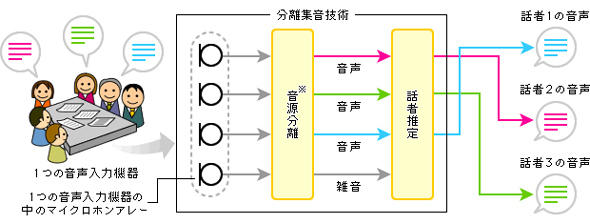
【第1段階】話者ごとの信号を分離
まずマイクアレイで拾った音を、音源(話者)ごとの信号に分離する。音を複数のマイクで捉えると、微妙にマイクの位置が違うために、それぞれのマイク出力は同じにはならない。しかし相関はしている。
それを数学的に表現すると、図4に見るような行列式で表される。つまり音源に「混合行列」を掛けたものが観測信号と考えるわけだ。ならば、混合行列の逆行列を観測信号に掛けてやれば音源信号の行列が分かることになる。その逆行列を「分離行列」といい、それを最適にする(推定する)ことができれば、音源信号がうまく分離できる。
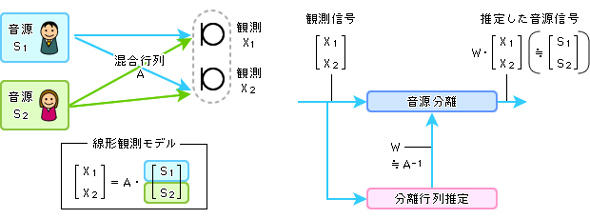
分離行列の推定のためのアルゴリズム(ブラインド音源分離)は既に20年ほど前から研究、開発されていて、録音後に時間をかけて処理したり、あらかじめ数十分程度の録音を行って学習したりしておけば推定が容易にできるのだが、実際の会議や対面サービスのシーンでそんな準備作業は不可能だ。
そこで準備作業を行わずに、観測信号に対して毎回分離行列を変化させて逐次的に学習していく方法が考えられるが、これでは計算量が多くてリアルタイム処理が難しい。観測信号をもっと大きくブロック分けしてブロックごとに分離行列を更新するようにすれば計算量を減らすことができるが、それでは分離精度が低くなる。
そこで、今回の技術のポイントの1つである「オンライン補助関数型独立ベクトル分析」(小野准教授と東芝の共同研究により開発)と呼ばれる方式が使われた。これは、複数マイクと話者との位置関係に起因する音声の、主に時間差によって音の方向(空間特性)を捉え、それを「補助変数」として利用する方法だ。
これなら非力なプロセッサでも高い性能で短時間に求められる。学習するのは空間特性であり、それをもとにしたタイミングで分離行列を変えるようにしたところ、リアルタイムの分離処理が可能になった。
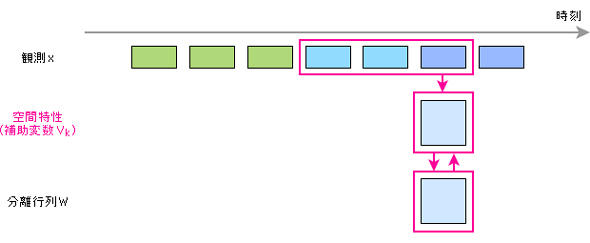
この新方式で、話者2人が同時に発言した音声を分離したとき、他方の話者の音声をどれだけ取りのぞけているかを測定したところ、従来の3dBから9dBと約2倍の改善をみたとのことだ。
Copyright © ITmedia, Inc. All Rights Reserved.