ディープラーニングを大幅短時間化「MN-1」って何?:5分で分かる最新キーワード解説(1/5 ページ)
2017年末の性能ランキングで高順位をマークしたプライベートスパコン「MN-1」。汎用GPUが開く、ディープラーニングの新機軸とは?
今回のテーマは2017年11月のスパコン性能ランキング(TOP500)で産業領域で国内1位(世界12位)を記録した民間のプライベートスパコン「MN-1」だ。学習に伴う膨大な計算量に対応する計算機資源が事業応用の壁になっている現在、汎用(はんよう)GPUを利用するハードウェアとオープンな学習フレームワークをベースにしたインフラが新たな突破口になりそうだ。
「MN-1」って何?
MN-1とは、IoT領域におけるディープラーニング、いわゆる深層学習を中心としたAI技術の事業化を目指して2014年3月に設立されたPreferred Networks(以下、PFN)が、NTTコミュニケーションズ(以下、NTT Com)およびNTTPCコミュニケーションズ(以下、NTTPC)のGPUクラスタなどの汎用ハードウェアをプラットフォームとして構築した、ディープラーニングを主な用途とするコンピュータシステムのこと。2017年11月のスーパーコンピュータ性能ランキング(TOP500リスト)の産業領域で世界12位、国内1位となった。
ちなみにPFNは、モビリティ事業分野におけるAI技術の共同研究・開発を加速させるべく、2017年8月にトヨタ自動車から100億円を超す追加出資を受けて大きな話題となった企業で、2017年12月にはファナックや博報堂DYHD、日立製作所、みずほ銀行、三井物産からも資金調達を行うなど、同社の持つ機械学習・深層学習技術がさまざまな業界から注目されている。
「ChainerMN」を搭載して学習性能は世界トップクラス
ランキング結果は、浮動小数点演算スピードを評価するためのワークロードを用いたベンチマーク試験であるLINPACKによるもので、MN-1は約1.39ペタFLOPSを記録した。これは研究用を含む全スパコンでは世界91位、国内13位であり、非凡な性能を発揮しているのは言うまでもない。
もっと注目したいのは、MN-1のハードウェアと表裏一体に組み込まれているディープラーニング用分散学習パッケージである「ChainerMN」の学習性能だ。この性能の客観的指標となるのは、画像認識性能評価のためのデータセットであるImageNetをResNet-50と呼ばれるネットワークに学習させるベンチマークだが、PFNが実施したテストでは、分散並列学習においてTensorFlowやCNTK、MXNetを凌ぐ世界トップ性能を示しているのだ(図1、図2)。
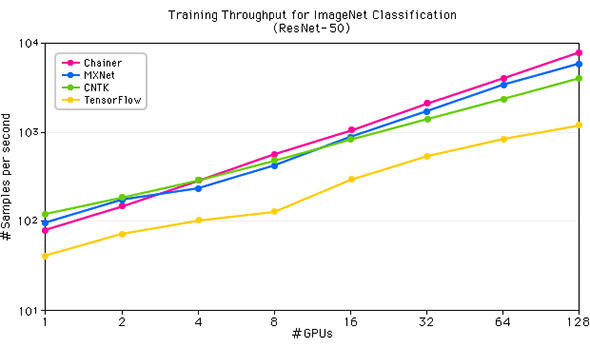
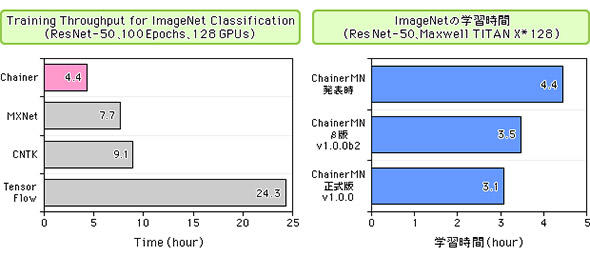
このような学習性能をもつChainerMNを搭載したのが「MN-1」だ。ハードウェアには、CPUにインテルXeon (E5-2667v4 8コア 3.2GHz)、GPUにNVIDIA Tesla P100を用いる、汎用ハードウェアで構成された空冷方式のコンピュータである。
類似した構成はTOP500リストの中では珍しくないが、Tesla P100を1024基(8GPUで1計算ノード、全体で128ノード)搭載し、GPU間のデータ伝送にHPC系のI/Oバス仕様InfiniBand FDR(最大スループット56Gbps)を利用しているところが少し目立つ。民間企業の計算環境として日本最大級のものでもある。
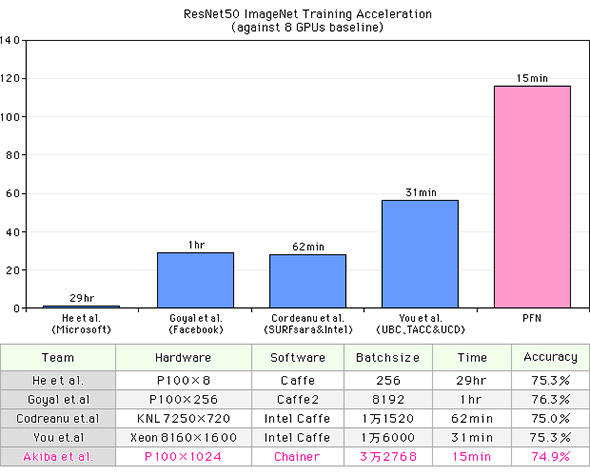
このMN-1を利用して、ImageNet(ResNet-50)の学習にPFNが挑戦した。その結果が図3である。これまで最速とされていたXeon Platinum 8160を1600台使用した研究では31分かかっていたものを、半分以下の15分で学習を終えることに成功したのだ。
Copyright © ITmedia, Inc. All Rights Reserved.