ディープラーニングを大幅短時間化「MN-1」って何?:5分で分かる最新キーワード解説(2/5 ページ)
2017年末の性能ランキングで高順位をマークしたプライベートスパコン「MN-1」。汎用GPUが開く、ディープラーニングの新機軸とは?
「ChainerMN」は何が他のフレームワークと違うのか?
PFNが開発、提供しているChainerは、Pythonベースのディープラーニング向けオープンソースフレームワークであり、上記の他フレームワークと並び、複雑なニューラルネットワーク設計を行うフレームワークとして世界的に利用されているものだ。
Chainerでは、TensorFlowなどが使う「Define and Run」と呼ばれる、ネットワークを作ってから学習する手法ではない。データを順方向に流して初めてネットワークができ、その逆向きの方向で「誤差逆伝搬」と呼ばれる計算を自動で行ってパラメータを更新して学習する「Define by Run」と呼ばれる方法をとる。この方法は「コードの最適化が難しい」といわれるものの、データごとにニューラルネットを作る用途では柔軟性が高いのがメリットになるとされている。
このChainerの技術を利用して、現在入手できるGPUクラスタをうまく利用するために拡張したのが「ChainerMN」であり、ChainerMNを大規模に実行するために構築されたのが「MN-1」だ。ChainerMNの処理は図4のようなイメージである。
「All-Reduce」処理により、各GPUを流れてきたデータが、一度集計されてその結果がそれぞれの流れに配られる仕組みをとる。All-Reduceには、NVIDIAのマルチGPU集合通信ライブラリであるNCCL(NVIDIA Collective Collection Library)を利用し、NCCLと相性がよい高速物理インタフェースであるInfiniBandが選ばれた。
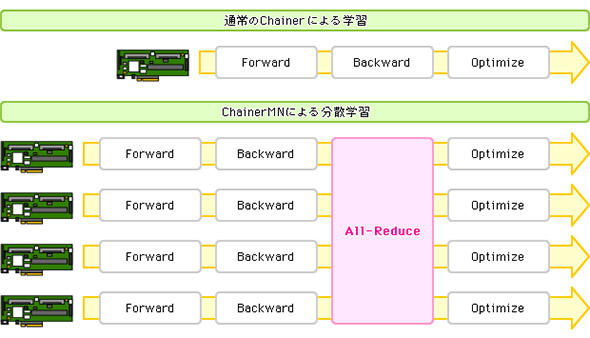
つまり「Chainer」が持つ柔軟性に加え、大規模なGPU分散処理環境に適合する高速通信インタフェースと、分散学習を効率的に実現する仕組みを組み合わせたことで、大幅な学習の時間短縮ができたというわけだ。
Copyright © ITmedia, Inc. All Rights Reserved.