脳で感じた印象を文字にする「fMRI脳情報デコーディング」とは?:5分で分かる最新キーワード解説(3/4 ページ)
脳情報はどうデコードされるのか?
では、fMRIで捉えた脳内の血流変化から、どのように知覚内容が解読(デコード)されるのだろうか。
fMRIでの計測とシーン記述
今回発表された実験では、まずMRI装置内で被験者(西田氏らの論文執筆時には6人。その後増えている)にCMなどの映像を約2時間視聴してもらい、脳活動をfMRIで計測した。その一方で、同じ映像を上記被験者以外の人々に視聴してもらい、各シーンの説明と受けた印象を文章にしてもらった。これで「脳活動の記録」と「シーン記述文章」の2通りのデータが出来上がった。
1万個の単語を100個の特徴により「言語特徴空間」にマッピング
これに先立ち、研究チームはGoogleが開発した「word2vec」という技術を利用し、Wikipediaの大規模テキストデータから「100次元の特徴ベクターをもつ言語特徴空間」を学習させていた。これは単語出現頻度や相関などの統計から導かれる単語と単語との意味の近さを、100次元の空間内での点と点の距離で表現できるようにするためだ(図3参照)。
つまり、「猫」と「犬」、「男」と「女」などの一般名詞で共通の特徴を多く持つ単語同士や、「住む」「建物」といった合わせて使われることが多い一般名詞と動詞は空間内の近い点として表現され、さらに「かわいい」「速い」などの名詞や動詞を修飾する形容詞も統計的に同時に使われる頻度が高い名詞や動詞に近いところに位置する点として表される。
あまり一緒に使われない単語同士は遠く離れることになる。その遠近差を評価する単語の特徴の数が「特徴次元」であり、特徴の数が100個であれば、単語の特徴は100次元の「特徴ベクター」として表される。特徴次元が多いほど詳細な単語の特徴が言語特徴空間で表現できるが、多すぎると言語特徴空間の学習が難しくなる(これは機械学習の基本部分だ)。ここでは1万語の単語のそれぞれの特徴を100次元の特徴ベクターとして学習し、単語と単語の関連性を表す「言語特徴空間」を作り出したわけだ。何かの単語は、この空間の中のどこかの1点にあたることになる。
単語の「特徴ベクター」と脳活動の対応づけを使って、新たな脳活動から単語を用いて知覚内容を推定
知覚や印象は感じた時点で言語化されるわけではないが、単語と結びついた意味の情報を持っている。つまり、そのような知覚や印象を表現する脳活動は、単語の意味と関係性をもち、脳活動が表現する情報は単語として可視化できるはずだというのがこの研究の前提だ。
そこで実験では、約2時間分記録してある被験者の脳活動データと、他の人々の「シーン記述」文章から抽出した単語の特徴ベクターとの対応関係を見いだすべく、機械学習技術を活用して取り組んだ。その結果、脳活動と単語の各特徴との対応関係を表す「重み係数」(対応関係が強ければ重く、弱ければ軽くなる係数)を導いた。
新たに計測した脳活動にその重み係数を適用して特徴ベクターを算出し、それぞれの単語の特徴ベクターとの遠近差から「ある脳活動と関連性のある単語」をスコアリングすることに成功した。一番スコアが高い単語が、その時のその人の知覚内容を表す単語と推定されるわけだ。たくさんの脳活動について、単語の対応が分かれば、推定とはいえ「脳活動の解読」ができたことになる。これが、西田氏らの「fMRI脳情報デコーディング」のあらましだ。
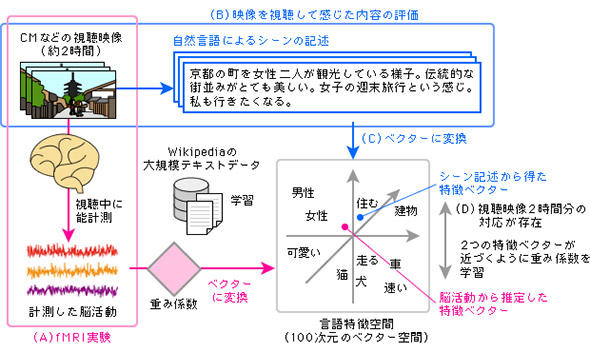 図3 fMRI脳情報デコーディングの方法の概念図(出典:NICT脳情報通信融合研究センター)
図3 fMRI脳情報デコーディングの方法の概念図(出典:NICT脳情報通信融合研究センター)このようにして出来上がった「脳情報デコーダー」を使い、CM映像などのに対する認知内容を、シーンごとに、従来は推定できなかった印象までも含めて、単語として取り出したのが今回の実験のポイントである(図4)。
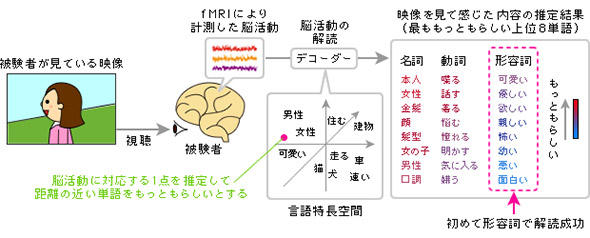 図4 CM映像などからの認知内容と印象の推定(出典:NICT脳情報通信融合研究センター)
図4 CM映像などからの認知内容と印象の推定(出典:NICT脳情報通信融合研究センター)Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- Appleがまたやらかし? チクられて分かった「iCloud+」の“最悪な仕様”:887th Lap
- AIがExcel作業を丸ごと自動化? 企業の定型業務を効率化へ
- 売上95%減、どん底のアスクルが旧システムを捨て、再起をかけた復旧の3カ月半
- Switch 2は「12人通話」でもなぜ軽い? 新機能「ゲームチャット」超低遅延の秘密
- Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
- タダで使える国会図書館の文字起こしツール、汚い手書き文字で精度をガチ検証
- 「RPAの二の舞」はもうゴメン……AIエージェントにささやかれる不吉な予感って?
- 現場に聞いた「IT関連50製品」のぶっちゃけ理解度 “浸透するツール”の共通点とは?
- アフラック約438万人漏えいだけではない 6月の5事案に見る、情シスが見落としやすい“穴”
- 「顧客管理システム作って」日本語で指示するだけでシステムが完成する最新AIとは?
アイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。