失った声を音声合成で取り戻す「ボイスバンク」とは?:5分で分かる最新キーワード解説(2/4 ページ)
これまでの音声合成技術の課題は?
ボイスバンクプロジェクトの発端は、山岸准教授が進めてきた音声の数理的な分析と合成の研究だ。その紹介の前に、少し音声合成の歴史を振り返りたい。
1950年代から始まった音声合成の研究は、最初は音と音とのつながりのルールを発見して、そのルールに基づいて音をつなげるルールベースの音声合成から始まった。これはTV番組や演芸で「宇宙人の声」や「ロボットの声」として滑稽なものとして演じられることがあるほど、不自然でぎこちないものだった。
それが今、電話やカーナビの音声案内などで聞かれるような、かなり自然な声音で流ちょうな発音になったのには、ITの発展により、膨大な量の音声データを取り扱えるようになったことが背景にある。
これらの音声合成には、特定の人の音声を録音し、そこから単音ばかりでなく単語や文章などを切り出して、テキストと対応するようにデータベース化した「音声コーパス」を作り、発声させたいテキストに合わせて必要な部分を抽出して接続する「波形接続合成」技術が使われる。
1980年代に生まれたこの波形接続技術が、現在の音声合成普及の原動力になった。「初音ミク」などのボーカロイドが人気を博しているが、これも波形接続合成技術の応用の1例だ。
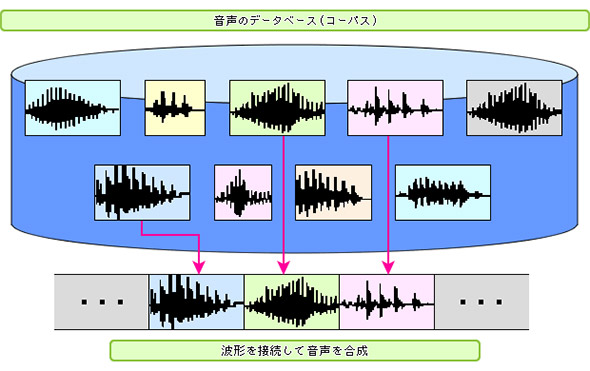 図3 波形接続合成技術のイメージ(出典:国立情報学研究所)
図3 波形接続合成技術のイメージ(出典:国立情報学研究所)しかし、この技術の課題は、ある人の声を再現しようと思うと、その人の声を長時間スタジオ録音する必要があることだ。自由に書かれた文章を発声させるには、10時間を超える録音データが必要になり、スタジオで録音し、後処理を加えてデータベース化して使えるようになるまで最低でも100万円程度、場合によってはその10倍もコストがかかるともいわれている。
そもそも現在発語が困難な患者の健常時の声をこの技術で再現するのには無理がある。また、大サイズのデータベースを使うため、音声合成処理をユーザーの手元の端末で行うには容量、性能的にも問題があった。
課題を克服した「HMM」を利用した音声合成技術
この課題克服の道を示したのが、1995年に名古屋工業大学の徳田恵一教授が提案した「HMM(Hidden Markov Model、隠れマルコフモデル)」を利用した統計的音声合成技術だ。
これは、同様に録音されてテキストとの関連付けがされたデータを利用するが、それをそのままではなく、「基本周波数(声帯の振動を反映、声帯が制御する声の高さ、アクセントに相当)」「スペクトル(声道の共振する周波数、母音や子音の各音に相当)」「リズム(発語のスピード)」といった要素で関数化する画期的な方法だった。
音声データベースを生の声ではなく、関数化された声(音響モデル)に置き換えることにより、格段にデータサイズが小さくなるだけでなく、パラメータを変えるだけでさまざまな音声を作り出せる。複数の人の声を混ぜ合わせることもできれば、どこにもない声を作り出すことも可能だ。
たくさんの人の声を平均化した「平均声」も合成可能になる。そして各国や地域の「平均声」を作っておけば、ほんの少しの本人の声でパラメータを調整することにより、その人の声に近い声色を作り出せる(話者適応)のだ。数分程度の本人の声のサンプルがあれば、かなり正確な本人の声が出力できる。
音声合成研究の世界では「どれだけ自然な音声が出力できるか」を多数の審査員が実際に聞いて評価する世界的な音声合成技術のリスニングテストが開催されるが、HMMを利用した音声合成技術はその大会で優秀な成績を収めた。その後世界の音声合成研究の流れが変わり、今では世界に多くの研究者が生まれ、たくさんの論文が続々と発表されるようになった。
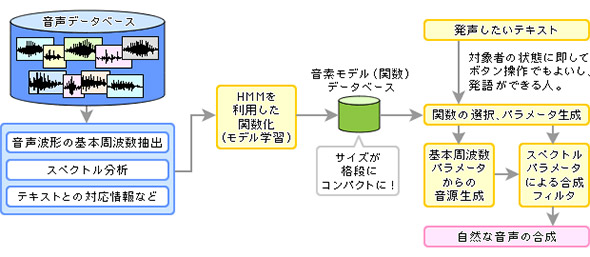 図4 HMMを利用した統計的音声合成のイメージ(出典:国立情報学研究所)
図4 HMMを利用した統計的音声合成のイメージ(出典:国立情報学研究所)Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- え、21日で37テラも? 高性能SSDを食いつぶす「あのAIツール」にご用心:886th Lap
- 「これからはモデルより自社に寄り添うAI」 Microsoft最新発表をプロはこう読む
- Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
- 370万種の魔手が迫る、高度化する「モバイルマルウェア」防衛策
- Arcserveが国内でクラウドバックアップ/DRサービス強化、自前でDCを提供
- 現実味を増す社会インフラへのサイバー攻撃 東武鉄道はどう対処したか
- コミュニケーションツールの利用状況(2020年)/後編
- 「AI OCRは“使えない”と思っていた」AI OCR活用で生産性2倍、残業対策を実現した企業の逆転劇
- 商船三井がiPaaSで巨大レガシー基幹システムから脱却 3年間の苦労と工夫を担当者が語る
- Microsoft Copilot vs. ローカルAI、最強の「文章要約AI」はどっち?:844th Lap
アイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。