情報分析基盤を内製したLIXIL、デジタル変革の道のりは「名寄せ」から?(3/4 ページ)
どうする? 顧客情報の「クレンジング」「名寄せ」を考えてみた
船水氏らは名寄せ実施に当たって、顧客情報をどこまで生かせるかを検討している。重複や不明、不正なデータなどを除いた「きれいな顧客情報」がどのくらい得られるかの検証だ。
その結果、メールなどでリーチできる顧客が約101万世帯も存在することが明らかになった。同社の場合、名寄せは左図のようなフローで実施している。


「名寄せ」の前に下準備として最も重い作業がデータクレンジングだ。システムが異なると、異字体の扱い、電話番号や郵便番号のハイフンや全角/半角などの数字の扱い、住所の分割位置の違いなど、運用ルールが大きく異なる。また、有効でないデータが入力されているケースでは適切にチェックして取り除く必要もある。こうしたことから、実際に名寄せを行う前に、格納データそのものを一定のルールの下で整えていく行程がデータクレンジングだ。
これらも実際の格納データの特性を分析し、登録データを無駄にしない方法を考えつつ、場合によっては潔く「きれいな無効データ」に変換するといった判断も必要になる。
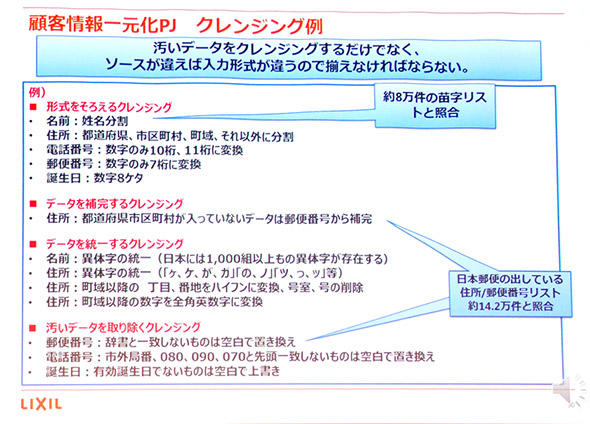
情報システム担当である船水氏は、自らクレンジングの方法を検討。公的な辞書情報と照合しながら、必要に応じて各レコードを一定のルールで修正、補完する方法を採用した。併せて無効なデータを取り除く処理も行っている。これだけの件数に複雑な処理を加えるため、処理の手法は事前に小さめのデータで幾つかの方法を評価している。
ここで単純なプログラムによる文字列操作と比較して、インメモリデータ分析が可能なApache Sparkを使った場合、約260倍も高速に処理ができたという。
「インメモリ処理ができるApache Sparkはデータ量の多いリストとのマッチングに適している、との知見が得られた」(船水氏)
住所のクレンジングでも同様の比較をしている。住所の場合、(1)郵便番号辞書を使った補完、(2)住所の適切な分割、(3)番地などの表記の統一、(4)住所に含まれる異自体の統一と、4つの処理を同時に実行する必要がある。処理をイメージした方には想像が付くと思うがこちらもやはり、メモリをうまく利用できるApache Sparkが得意とする領域。こちらは処理が複雑だったこともあり、Pythonプログラムによる操作と比較すると878倍も高速だったとしている。
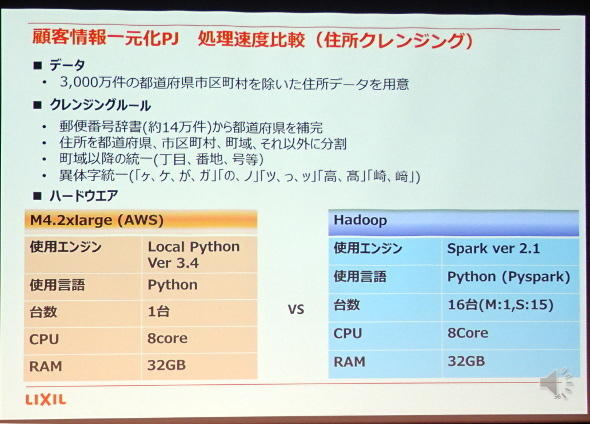 住所クレンジング方法の検討
住所クレンジング方法の検討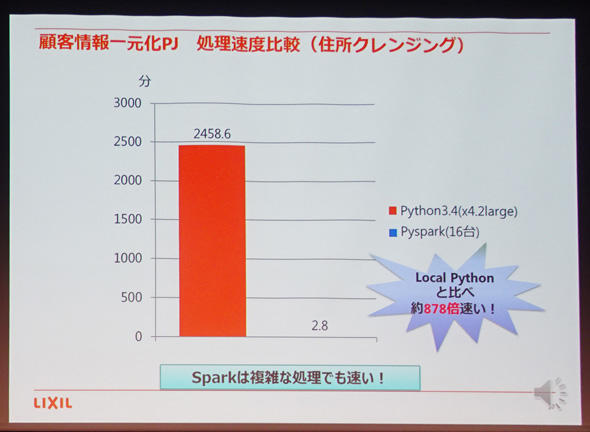 検証結果
検証結果こうした検証を経て、実際の顧客情報DBの「名寄せの条件」と実施環境を決定、実際の運用では、全体の約60%が名寄せできている状況だ。


関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- タダで使える国会図書館の文字起こしツール、汚い手書き文字で精度をガチ検証
- Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
- 「RPAの二の舞」はもうゴメン……AIエージェントにささやかれる不吉な予感って?
- GitHubの解説読んだだけなのに……まさかのトロイの木馬に感染、一体なんで?:885th Lap
- 定番データベースを捨て、あのコーディングAIにエンジニアたちが群がる理由
- Geminiで「AIを使いたい現場」と「ダメと言う会社」のギャップを埋める方法
- 社長のメールが妙に丁寧……AI時代の不審メールを見抜く社員は何に違和感を抱く?
- 23歳の期待のエースが突然「辞めたい」 ノーコードが退職でも活躍ってどういうこと?
- PC260台をほぼ1人で守る物流企業が「ランサム対策基盤を1カ月で刷新」でやったこと
- 舞鶴市「脱Windows」で6億円削減 1人1日82分を時短したGoogleツールの使い方
アイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。