“普通の会社”にAmazon級のデータ駆動ビジネス基盤は作れるか?(3/3 ページ)
既存システムとのつなぎ込みも「ユーザーが迷わずに使える」
12月にも開始を予定しているSAP Data Hubのトレーニングプログラムには、ビッグデータ関連のシステムコンサルティングやインテグレーションを手掛けるヴピコが協力する予定だ。
ヴピコ 統括部長 アーキテクチャー ダミアン・コントレラ氏は、SAP Data Hubの利点として、分かりやすさやユーザー自身による取り扱いの簡便さを挙げる。
「ストリームデータだけを考えたり、バッチ処理だけであったりといった個別の目的に対応する機能であれば、実はオープンソースソフトウェアを含め、多様な選択肢がある。しかし、一般的な企業では、これらをどう組み合わせて利用していけばよいのかを判断しにくい。利用するには専門的な知識が必要であり、技術トレンドの動きも流動的であるため、常に自主的に情報をキャッチアップできる体制でなければ対応できない」(コントレラ氏)
コントレラ氏が指摘するのは、例えばデータフローオーケストレーションツール「Apache NiFi」、ストリームデータ処理基盤「Apache Storm」といったオープンソースソフトウェアでも個別の機能は一定の品質で利用できるということだ。あるいはHadoopディストリビュータのサポートを受ければ、ビッグデータ処理基盤自体を、企業ITにふさわしい品質で運用できるかもしれない。
しかし、一般企業では、他部門の長期的な実績データの分析結果と自部門の管理システムが持つデータを突き合わせたりといった、既存のエンタープライズシステムが持つデータとの連携や参照といった使い方が必要なことが多いと考えられ、エンタープライズシステムとつなぎ込む部分を、一定のルールの下で解放し、利用させる必要がある。
「別システムに保管する過去5年の実績データとERPが持つ直近1カ月の取引データを自力で照合する」といった場合には、データ加工や連携のためのツールを開発する必要がある。
この点で、SAPの製品ポートフォリオであれば、SAP Dat Hubを使って加工データを基幹業務システム側のデータウェアハウスに供給できるし、ETLツール「SAP Data Services」を利用すれば、既存のSAP資産とのデータ連携も効率よく実行できるようになっている。
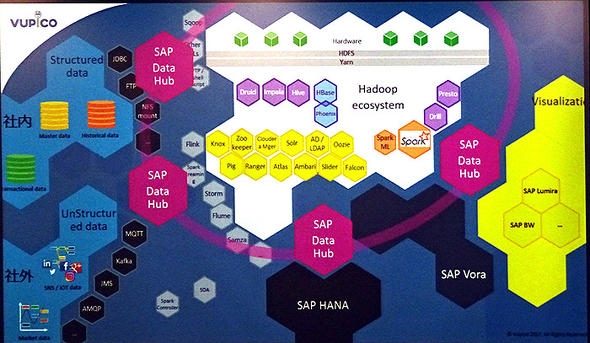 データ処理基盤をOSSでまかなうことの難しさ データ処理基盤を自力で構築する場合には多様なオープンソースプロダクトを組み合わせる必要がある,データ処理基盤をOSSでまかなうことの難しさ データ処理基盤を自力で構築する場合には多様なオープンソースプロダクトを組み合わせる必要がある
データ処理基盤をOSSでまかなうことの難しさ データ処理基盤を自力で構築する場合には多様なオープンソースプロダクトを組み合わせる必要がある,データ処理基盤をOSSでまかなうことの難しさ データ処理基盤を自力で構築する場合には多様なオープンソースプロダクトを組み合わせる必要があるこの他、データフローの処理についてもGUIでパイプラインを設計する機能や、データソースを一元的に管理できるポータルも持っており、「ユーザー企業が迷いにくい環境が用意されている」(コントレラ氏)。
SAP Data Hubがラインアップに加わったことで、既存のSAPユーザーは、SAP製品群を離れずに既存のシステムと連携したデータ処理基盤を利用できるようになる。これが、SAPユーザーにとって最大の価値になるだろう。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- AIがExcel作業を丸ごと自動化? 企業の定型業務を効率化へ
- Switch 2は「12人通話」でもなぜ軽い? 新機能「ゲームチャット」超低遅延の秘密
- 現場に聞いた「IT関連50製品」のぶっちゃけ理解度 “浸透するツール”の共通点とは?
- タダで使える国会図書館の文字起こしツール、汚い手書き文字で精度をガチ検証
- カクヤス「30年物の泥沼システム」をAIでどう解読? 現場が思いついた“ある考え”
- 社長のメールが妙に丁寧……AI時代の不審メールを見抜く社員は何に違和感を抱く?
- 「これからはモデルより自社に寄り添うAI」 Microsoft最新発表をプロはこう読む
- 生成AI活用者の約7割は「チャット止まり」 成果を実感する人の使い方とは
- 他の会社はAIどう使ってる? 他社のスキルをタダで盗める交流会に潜入してみた
- 手作業で消耗する人とそうでない人の差 全員がAIを「当たり前に使う職場」の作り方
アイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。