匿名加工情報とは? 基礎概念、利用用途を理解する:IT導入完全ガイド(2/3 ページ)
大きな期待を集めるデータ匿名化技術「k-匿名化」
データを匿名化するための手法には、さまざまなものが存在する。最も単純な方法は、「個人情報が含まれるデータベースの項目を丸ごと削除してしまう」というやり方だ。全ての個人情報を削除してしまえば、個人が特定される危険性は限りなくゼロに近づく。しかしそこまで削除してしまうと、データそのものの利用価値がなくなってしまう。
一方、必要最低限の個人情報だけをマスキングすれば、データの特性はさほど大きく変わらず、ビッグデータ分析の精度もある程度担保される。しかし必要最低限のマスキングだけでは、今度は他のデータと照合することで容易に個人が特定できてしまう。
このようにデータ匿名化は、常に「匿名性」と「データの有用性」のバランスが問題となる。単純なデータの削除やマスキングでは、どちらかを重視すればもう片方がおろそかになってしまう。そこで、この両方を高い水準で両立できる匿名化のアルゴリズムが、長年統計学の分野で研究されてきた。
その過程では、さまざまなデータ匿名化の手法が編み出されてきたが、近年特に注目を集めているのが「k-匿名化」と呼ばれる技術だ。
注目のデータ匿名化手法「k-匿名化」
k-匿名化とは、幾つかの個人情報の項目を、データが曖昧になるよう加工することで、同じ個人情報の属性を持つデータが必ずk件以上存在するように匿名化を行うという手法。言い換えれば、個人が特性される可能性を「k分の1」にまで低減するということだ。
k-匿名化は2006年ごろに学会で初めて論文が発表され、その後各研究機関やベンダーで実用化のための研究が進められてきた。k-匿名化はシステムに高い処理負荷を掛けるため、特に処理時間短縮のためのさまざまな方法が研究され、その一部は既に実用化されている。
現在では複数のベンダーから、k-匿名化を採用したデータ匿名化ソリューションが提供されている。単純な削除やマスキングと比べ、はるかに個人を特定されにくい形にデータを匿名化でき、かつデータの分布や特性を残すことができるため、ビッグデータ利活用のためのデータ匿名化の手段として大きな期待が集まっている。
k-匿名化は、その優れた匿名化アルゴリズムはもちろんのこと、kの値で匿名化の強度を定量的に示せる点が高い評価を受けている。k値が大きくなれば匿名性は高まるが、その分データの有意性は低くなる。逆にk値を小さく取ればデータの有意性は高まるが、同時に個人特定のリスクも高くなる。また、データ匿名化の強度を明確に示せることは、万が一情報漏えい事故が発生してしまった際の対外的な説明責任を果たす上でも有効な手段だといえる。
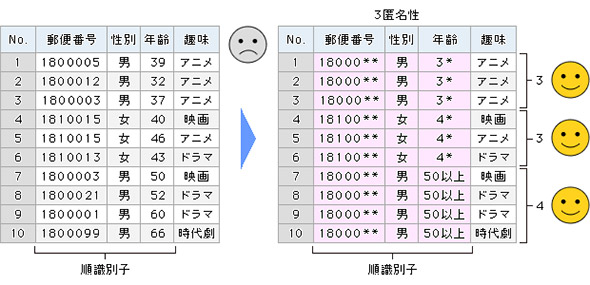 図2 k=3とした場合の匿名化のイメージ 日立コンサルティング「プライバシー保護データマイニング(PPDM)手法の種類、特徴を理解する」図2を元に編集部で再構成
図2 k=3とした場合の匿名化のイメージ 日立コンサルティング「プライバシー保護データマイニング(PPDM)手法の種類、特徴を理解する」図2を元に編集部で再構成関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- タダで使える国会図書館の文字起こしツール、汚い手書き文字で精度をガチ検証
- Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
- 「RPAの二の舞」はもうゴメン……AIエージェントにささやかれる不吉な予感って?
- 「前任者が不在」でも大丈夫 PCログからAIがマニュアルを自動作成する時代へ
- Geminiで「AIを使いたい現場」と「ダメと言う会社」のギャップを埋める方法
- 舞鶴市「脱Windows」で6億円削減 1人1日82分を時短したGoogleツールの使い方
- 手作業で消耗する人とそうでない人の差 全員がAIを「当たり前に使う職場」の作り方
- 「会議多過ぎ問題」の正体 職場の会議は何のために開かれているのか
- 古いシステムはなぜ残るのか Windows 10とAS/400に見る移行の壁
- 「IT人材がウチの会社を辞める理由」 “給料が安いから”は2位、1位は?
アイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。