暗号化DBを復号せずにデータ分類する「暗号化データマイニング」とは?:5分で分かる最新キーワード解説(3/5 ページ)
現実的な時間で統計処理を可能にする新発想
完全準同型暗号でロジスティック回帰分析すると「年」単位の時間が必要
しかし、ロジスティック回帰分析のような計算処理を完全準同型暗号を用いて暗号化されたデータで行おうとすると計算処理が極端に増加する。NICTの専門家によると「データ処理にどれだけの時間がかかるのか、全く想像もつかない」というほどだ。しかし、NICTではその処理をできるだけ軽減するために2つの突破口を見いだした。
2つの工夫で1億件のデータも30分で分析可能に
その1つは、機能に制約のある準同型暗号を利用することだ。完全準同型暗号はコンピュータに計算できる処理であれば何でもできるが、計算が非常に遅いというデメリットがある。その代わりに機能に制約があるが高速に計算が可能な準同型暗号を利用することで大幅な高速化が期待できる。
もちろん、機能に制約があるため、そのままではロジスティック回帰分析に使う指数関数や対数関数を計算することができない。そこで、それらの関数を2次関数(多項式)で近似することで、高速な準同型暗号でも計算が可能な手法を開発した。
つまり、本来の計算式よりも大幅に計算を簡略化しながら、正確ではないが実用上問題ないレベルの近似値を、暗号化データで求める手法を導き出したのだ。これにより、暗号化データであっても高速なデータ処理が可能になった。
もう1つは、サーバへの負荷をできるだけ少なくする工夫だ。元データをそのまま暗号化してサーバに送る(図2上)のではなく、データ提供者の側であらかじめデータ加工処理(2次関数計算の一部)を行うようにして、その結果を暗号化して送るようにした(図2下)。
サーバでは暗号化データの加算を行うだけにして、その中間結果(暗号化されている)をデータ分析者に渡す。ロジスティック回帰分析に必要な2次関数を復号したデータ分析者が手元で計算して最終結果を得るという運用方法をとることにした。この結果、NICTが開発した準同型暗号「SPHERE(スフィア)」を用いたシミュレーションでは、1億件のデータを汎用の計算サーバ1台で30分以内で処理可能なことを確認したという。
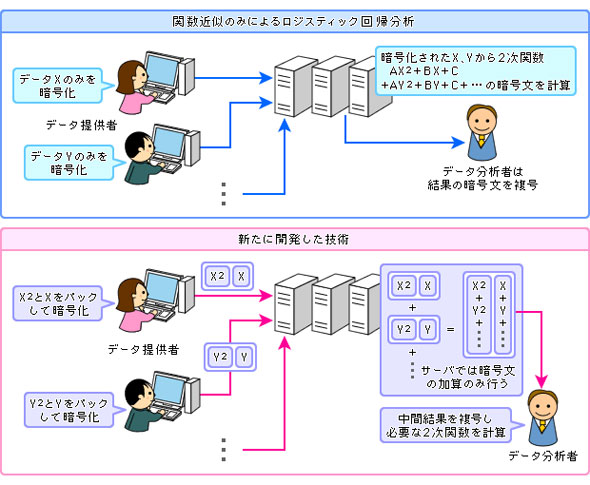 図2 データ提供者側でのデータ加工を行うことで計算量を大幅軽減(資料提供:NICT)
図2 データ提供者側でのデータ加工を行うことで計算量を大幅軽減(資料提供:NICT)関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- AIがExcel作業を丸ごと自動化? 企業の定型業務を効率化へ
- Switch 2は「12人通話」でもなぜ軽い? 新機能「ゲームチャット」超低遅延の秘密
- 現場に聞いた「IT関連50製品」のぶっちゃけ理解度 “浸透するツール”の共通点とは?
- カクヤス「30年物の泥沼システム」をAIでどう解読? 現場が思いついた“ある考え”
- タダで使える国会図書館の文字起こしツール、汚い手書き文字で精度をガチ検証
- 「これからはモデルより自社に寄り添うAI」 Microsoft最新発表をプロはこう読む
- KDDIメール基盤で最大1422万件に影響 ファイル転送やランサム被害も相次ぐ
- 他の会社はAIどう使ってる? 他社のスキルをタダで盗める交流会に潜入してみた
- 生成AI活用者の約7割は「チャット止まり」 成果を実感する人の使い方とは
- アース製薬「IT未経験者が1週間でアプリ構築」 業務デジタル化クラウドで現場改革
アイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。