暗号化DBを復号せずにデータ分類する「暗号化データマイニング」とは?:5分で分かる最新キーワード解説(2/5 ページ)
データを分類する機械学習技術「ロジスティック回帰分析」
NICTの実験では、まず糖尿病に関する公開実データ(カリフォルニア大学アーバイン校(UCI)機械学習リポジトリ)を用いて、各種計測データから糖尿病との関係を割り出す機械学習のプログラムを作成した。これは「ロジスティック回帰分析」と呼ばれる手法で、図1はそのうち血糖値とBMIを手掛かりに、ある人が糖尿病であるか否かを自動判定した結果の例だ。
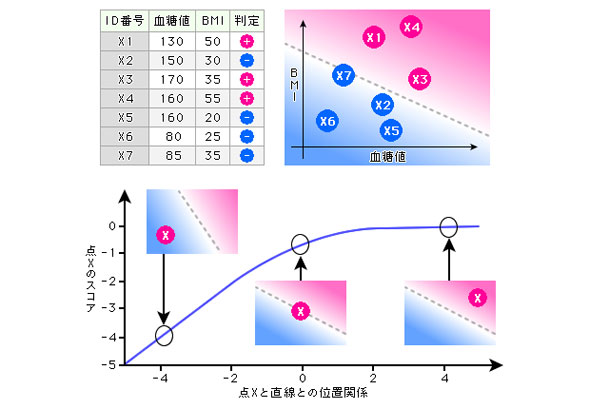 図1 血糖値とBMIから糖尿病か否かを推定する「ロジスティック回帰分析」(資料提供:NICT)
図1 血糖値とBMIから糖尿病か否かを推定する「ロジスティック回帰分析」(資料提供:NICT)サンプルデータを2次元のグラフにプロットすると、図1上のように、グラフのある境界(直線)を境に、糖尿病患者と健常者がくっきり分かれて分布している。その分布の仕方から境界となる直線を計算で導き出すのがロジスティック回帰分析による学習だ。
それは図1下のように各点に対して直線との位置関係に応じたスコアを割り振り、その合計値が最大となるように調整する。いったんこの直線が定義できると、以降はプログラムに計測データを入力すれば、その人が上の図上で言えば赤いエリアにいるのか、緑色のエリアにいるのかを自動判定できることになる。その誤差が一定範囲内なら十分実用的な診断法になるというわけだ。
データの位置関係とスコアの関係は対数関数と指数関数を組み合わせたもの。これはデータ分析の基本となっている一般的な技術であり、ビッグデータ解析を行うアナリティクスソフトウェア(SASやSPSSなど)に組み込まれて、疫学研究のリスク要因研究や各種予測分析によく利用されている。しかし、これを暗号化したまま行おうとすると、高いコンピュータ能力が必要になる。
従来の暗号化データを計算処理するときは、どこかで必ず復号する必要あり
現行の市販ソフトウェアなどは平文のデータを対象としており、データは暗号化されて保管していても、計算処理を行うときにはいったん復号して平文に戻す処理がいる。それがたとえメモリ上だけであっても、管理者がメモリをダンプしたり、不正プログラムがストレージに書き込んで外部送信したりする可能性がゼロではない。そこで、暗号化されたデータを暗号化されたまま計算処理する仕組みが求められている。
それを実現したのが暗号化データマイニングだ。従来は、暗号化されたデータに対して計算処理をすることは困難だったのだが、暗号化されたデータ同士を加法乗法演算可能な(コンピュータの論理演算のXORとANDが処理できる、つまりデジタルデータならどんな計算でもできる)画期的な暗号技術「完全準同型暗号」が2009年に開発された。
この技術によれば、例えば、a、b、cという数値をある暗号化鍵で暗号化したデータがあるとして、その平均を暗号化されたまま計算処理でき、その結果であるdも同じ鍵で暗号化された状態で出力される。平均計算をリクエストしたユーザーは、その結果の暗号化されたデータを受け取り、暗号化鍵で復号すれば平均値dを知ることができる。しかしその結果となる元データがa、b、cであることを推理することはできないという仕組みが作れる。
例えば、クラウドサービスで多数のユーザーのウェアラブルデバイスなどから生体情報を収集し、本人に健康管理情報を提供するとともに統計的な情報として活用しようとする場合などには大変好都合だ。
ユーザー個々の生のデータは平文では通信経路上やストレージ、メモリ上に存在せず、復号の権限を持った人(復号鍵を持った人)だけが、統計結果のみを平文にできる。統計結果からは、どの人の数値がいくらだったのかは分からない。つまり生のプライベートデータが外に出る部分が全くない。これはプライバシー問題や機密情報漏えい問題を技術的に解決する決め手になり得る。
なお、糖尿病か否かを自動判定するNICTの実験では、血糖値とBMIだけを用いた場合だと、暗号化なしのオリジナルのロジスティック回帰分析処理で正解率は約77%、暗号化データの場合で約76%だった。また年齢や血圧などの8種類のデータを用いた場合ではオリジナルの場合も暗号化データの場合も80%前後と、ほぼ同じ結果が得られている。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- ニチレイや日本交通でシステム遮断 冷凍食品の出荷もタクシーの配車も止まった1週間
- ジュラシック・パークに映る“あのPC”、実はとんでもないマシンだった:889th Lap
- ゼロから分かる「Claude」の教科書 ChatGPTと比べて分かった強みとは?
- AIで脱ブラックボックス コード解析とドキュメント自動生成の新サービス発表
- 「機能は分かるが業務への落とし込み方が分からない」 加瀬HD調査で見えた“AI定着の壁”
- フジッコ、生成AIサービス「Lightblue」本格導入 決め手となった3つの評価軸とは
- 中外製薬「社員1人にAIエージェント10体」作戦で成果倍増を目指す、AI使いこなし術
- PC260台をほぼ1人で守る物流企業が「ランサム対策基盤を1カ月で刷新」でやったこと
- SSDの限界を超える「ReRAM搭載SSD」とは?
- RPA、読者が1番利用しているツールは? 実態調査
アイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。