AIの精度を保証する「機械学習品質マネジメントガイドライン」とは?
人の生死や資産に直結する領域にまで手を伸ばそうとしているAIだが、その判断や予測の精度を左右する機械学習の品質については気掛かりなところ。そこで登場したのが、世界でもほとんど例のない、汎用的な品質管理ガイドラインだ。
「機械学習品質マネジメントガイドライン」の目的は?
AI(人工知能)の適用は、自動運転をはじめとする機械制御や故障予測、マーケティング分析や投融資判断、個人の信用査定などビジネスにクリティカルな領域へと拡大を続けている。その中でAIシステムに今後ますます厳しく問われるのが安全性や正確性だ。「AIが入っているから大丈夫」というごまかしは、今は通用しない。
どうすればAIシステムの品質を保証できるのだろうか。誰もが納得する答えはまだないようだが、品質を議論するための素地は着々と固められてきている。その取り組みの一つが、今回紹介する「機械学習品質マネジメントガイドライン」だ。
2020年6月30日に公開された同ガイドライン(第1版)は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)から研究を受託した国立研究開発法人産業技術総合研究所(産総研・AIST)と大学共同利用機関法人情報・システム研究機構国立情報学研究所(NII)が、外部有識者らとともにとりまとめたもの。機械学習利用システムの企画段階から運用までのライフサイクル全体にわたる品質活動プロセスを通して、品質目標の設定や計画、確認、品質保証、管理をするための参考として利用できる。
このガイドラインの意義について、作成に携わった産総研・サイバーフィジカルセキュリティ研究センターの大岩 寛氏(研究チーム長)は「(AIシステムの)ユーザー、開発者、ベンダーなど関係者間で『コミュニケーションのポイント』を押さえてもらいたい」と話す。
ガイドラインが示す「機械学習品質」とは?
大岩氏の言うコミュニケーションのポイントとは何だろうか。同ガイドラインの内容に沿って挙げてみよう。
ガイドラインでは、機械学習システムの品質を「利用時品質」「外部品質」「内部品質」の3点に整理している。
「利用時品質」は、エンドユーザーに提供される製品やサービス全体の品質のことだ。この品質をどこまで保証できるかが、品質管理のキモになる。
「外部品質」は、利用時品質を確保するための各種の構成要素に要求される品質のことだ。構成要素に機械学習システムが含まれる際に、その外部品質をどのように確保するのかが、本ガイドラインの主眼となる。
「内部品質」は、構成要素それぞれに固有の特性としての品質のことだ。
図1のように、利用時品質は構成要素全体の外部品質によって実現され、外部品質は複数の構成要素による内部品質によって実現されるイメージとなる。
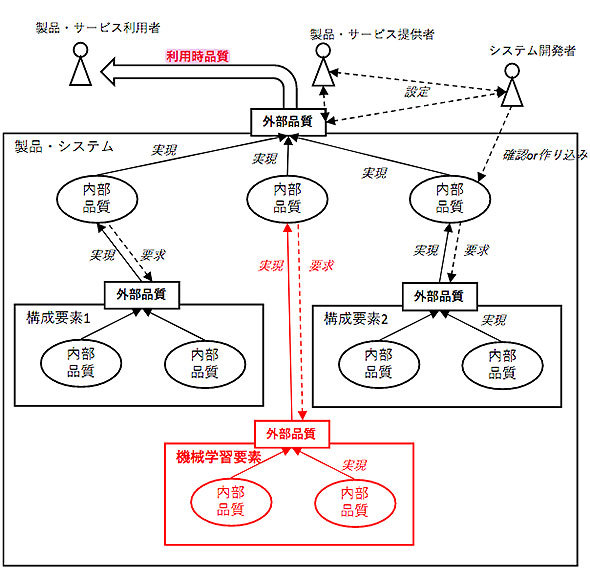 図1 利用時品質・外部品質・内部品質の階層的な品質モデル(同ガイドラインより)
図1 利用時品質・外部品質・内部品質の階層的な品質モデル(同ガイドラインより)外部品質特性として実現目標にするのは3特性
ガイドラインの注目ポイントは、機械学習要素の外部品質特性の軸として「リスク回避性」「AIパフォーマンス」「公平性」の3つを抽出し、それぞれに品質レベルを設定しているところだ。
特性1 リスク回避性
例えば自動運転に必要な物体認識で障害物を見落としたり、有価証券取引での不正発注を見逃したりといったリスクを避けられるかどうかは、時には人命や大きなビジネス損失につながりかねない重要な観点だ。これにはIEC61508などの既存規格にもレベル分け(4段階のSIL(SIL=Safety Integrity Level))があるが、従来は軽微なリスクとしてまとめられてしまうレベルのリスク(SIL 1以下に相当)を細分し、7つのレベルのAISL(AI安全性レベル)を定義した。
特性2 AIパフォーマンス
製品・サービスの正答率・適合率・再現率などの性能指標を設定しているか否か、性能指標の充足が強く求められるかに応じて3段階にレベルを定義した。性能指標充足が必須、または強い前提である場合などはAIPL2、一定の性能指標を目指すが、品質をモニターしながら性能向上のための運用を許すなど少し緩い要求の場合はAIPL1とし、PoC(Proof of Concept:概念実証)や性能指標の発見そのものを目的とする場合はAIPL0とした。
特性3 公平性
AIシステムでは、一定の社会規範性や倫理性が特に強く要求される。例えば偏りのあるデータで訓練し、運用において人種や性別などによる差別(偏り)が生じるようでは失敗だ。ところが設計時点では「公平な判断」を実現したつもりでも、実装過程や学習結果により公平性が保たれなくなる可能性がある。
そこで「公平性」を「機械学習利用システムの出力に対して、ユーザー視点から見て望ましくない偏りがないことなど出力全体の分布に関して一定の統計的性質が要求されること」と定義し、法令などによって公平な取り扱いを強く要求・想定される場合などをAIFL2、サービスが偏りを持たないことを説明できないと運用の障害になる場合などをAIFL1、公正性が要求されない場合をAIFL0とレベルを定義した。
外部品質をどのようなレベルで実現するのかは、システムの目的や性格によって異なり、必ずしも常に上位レベルを目指すことが求められるわけではない。外部品質のレベル定義は、特に開発発注者と開発者の間で適切な品質を見極めるための助けになりそうだ。
利用時品質を実現する要素としての外部品質と、後述する内部品質との関係を図示したのが図2だ。利用時品質は、上記3つの外部品質特性と、同ガイドラインとは別の既存規格や関連ガイドラインなどに記載されている内容を参照して実現可能になる。3つの外部品質特性を実現するのが、次の図の下部に示された8つの内部品質特性である。
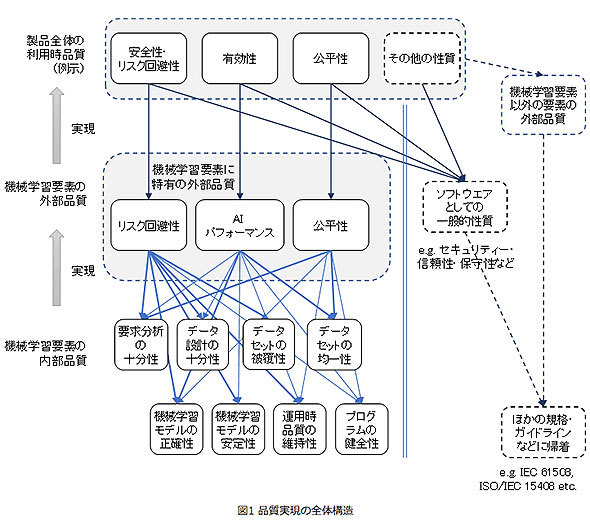 図2 製品品質実現の全体構造(同ガイドラインより)
図2 製品品質実現の全体構造(同ガイドラインより)
「リスク回避性」と「AIパフォーマンス」に関する内部品質8特性
今回のガイドラインでは「リスク回避性」と「AIパフォーマンス」に対応する内部品質特性として、図3に見るような8項目を抽出している(「公平性」については今後追加)。それぞれの項目は客観的に計測や分析を行って品質を評価する軸となる。以下ではそれぞれについて簡単に説明する。
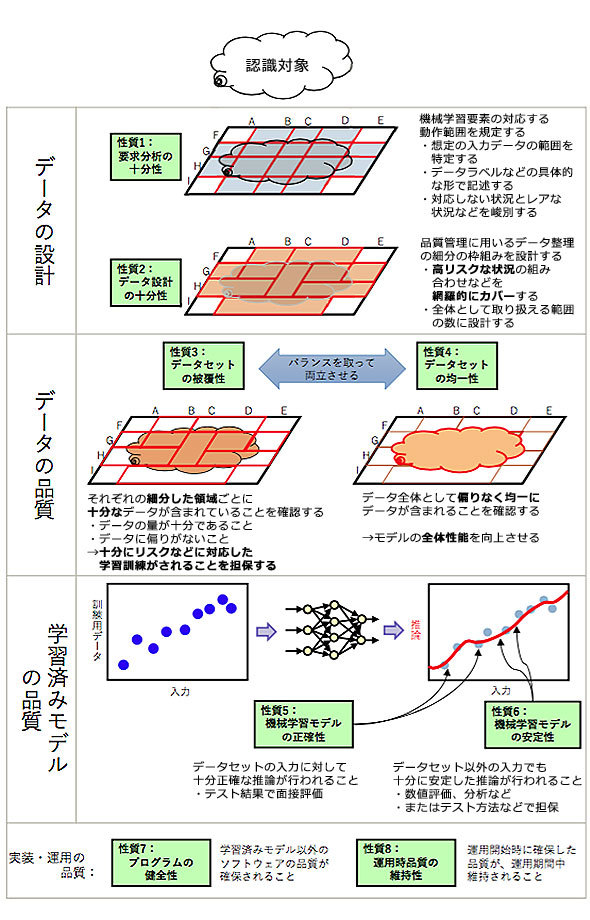 図3 注目すべき8つの内部品質特性
図3 注目すべき8つの内部品質特性性質1 要求分析の十分性
大岩氏が最も重要だと強調するのが「要求分析」だ。一般のIT開発でも要件定義がおろそかだと例外処理が十分組み込まれずに不具合を出すことが往々にしてあるが、機械学習利用システムでは何が「例外」なのかも分からないことが多くなる。どんな状況にも対応できる自動判断などを実現するには、莫大(ばくだい)な量の偏りのないデータで訓練する必要があるが、現実的には非常に難しい。そこでガイドラインでは要件を具体的な言葉で箇条書きのように分類整理し、それらの組み合わせを把握する手法を提案している。
例えば小売店の販売傾向の予測システムなら、曜日や天候、時間帯、季節、近隣のイベントなどを機械学習の要素として、それらの組み合わせで1つの状況が表現できると考える。どのようなデータ属性(アトリビュート=環境条件の特徴項目)を対象にして、どこまでのソリューションをするのか、またそのためのデータを収集できるかなどが品質を測る観点になる。
そのように、機械学習要素が対応するべき要求内容の対象を明らかにすること、そしてその範囲の限定を明示することが大事だ。要求分析の十分性は他のIT開発でも重要だが、機械学習システムで利用状況の想定に見落としがあると、開発途上でそれに気付くことが難しく、誤動作や誤判断が生じた時に初めて発見されるようなことが起きやすい。しかしあまりに詳細な利用状況分析を開発時に行うのでは機械学習の意味がない。バランスをとり、要求分析の詳細度を適切に設定することが重要だとガイドラインは述べている。
なお、ガイドラインでは内部品質の8つの性質それぞれの項目で、各外部特性のレベルに応じた内部品質要求事項がまとめられている(性質項目それぞれに要求事項が記されている)。
性質2 データ設計の十分性
上記を踏まえ、利用場面を考慮して十分な訓練用データやテスト用データを確保するためのデータ設計が必要となる。対象とする属性数が多すぎて組み合わせ爆発で評価不能になったりしないように、テスト工程までの着目するアトリビュートの組み合わせの数や内容について適切な網羅性を考えて設計する。
性質3 データセットの被覆性
データの不足による学習不足や、偏ったデータによる特定の状況への学習漏れが起きないように十分なデータが与えられているかどうかが重要だ。例えば猫を画像認識するシステムなら、三毛猫などの特定種だけが学習対象になっていて、その他の猫や犬など他の小動物の画像データが使われていなければ、正当な認識はできないだろう。抜け漏れなく、十分な量のデータを用意する必要がある。
性質4 データセットの均一性
一般に入力環境に対して均一に抽出したサンプルを訓練用データセットとして用いれば予測精度は高くなるとされる。偏りなく、均一なサンプルを用いているかどうかがこの観点である。ただし実際の応用やそこで求められる品質特性によっては、被覆性のほうが重要な場合があるので、ケースによって考慮する。
性質5 機械学習モデルの正確性
学習データセット(訓練用データ、テスト用データ、バリデーション用データからなる) に含まれる具体的な入力データに対して、機械学習要素が期待通りの反応を示すこと。
性質6 機械学習モデルの安定性
学習データセットに含まれない入力データに対して、機械学習要素が学習データセット内のそれに近いデータに対する反応と十分に類似した反応を示すかどうか。
性質7 プログラムの健全性
機械学習の訓練段階に用いる訓練用プログラムや、実行時に使われる予測・推論プログラムが、与えられたデータや訓練済み機械学習モデルなどに対してソフトウェアプログラムとして正しく動作するかどうか。これには一般的なソフトウェアへの品質要求も含む。
性質8 運用時品質の維持性
要求分析の十分性と並び、重要性が高いのが運用時品質の維持性だ。これは、運用開始時点で充足されていた内部品質が、運用期間中を通じて維持できるかどうかという観点である。例えば物体認識による工場の外観チェックでは、運用期間中に製品や設備などの劣化状況を追加学習しないと誤判断につながる場合がある。そのように、システム外部の環境変化に追従して(追加学習・再訓練して)訓練済み機械学習モデルなどを変更できるかどうか、そして変更によって品質が劣化することがないかどうかといった観点だ。
ガイドラインを利用するメリットは?
以上のように整理されたポイントが記されていることにより、同ガイドラインは機械学習利用システムの関係者(開発発注者、開発者、サービスプロバイダー、エンドユーザーなど)それぞれの認識にズレが生じないよう、同じ言葉で、共通した視点で、明確な目標設定や要件定義、実装の仕方や運用の方法などが議論できるようになる。いわば、このガイドラインは開発のための「合意ツール」となる。従来は曖昧な合意に基づいた試験的な開発も多かったが、現在は具体的なシステム利用成果が求められる時代になっている。それに伴い、関係者間の責任分界の設定・明確化も求められる。これからの幅広いAI社会実装においては、こうした汎用的なガイドラインが必要だ。
今後の計画と、おすすめ参照資料
産総研では、第1版に不足している部分を補う第2版の公開を本年度中に計画しており、さらに本年度中に自動運転と工場の外観検査に用いられる物体認識に関する機械学習システムの具体例をまとめたレファレンスガイドを発行予定だ。その後、特定のユースケースに沿ったレファレンスガイドを順次作成していく。
また品質管理のライフサイクル全般の支援を目的にしたプログラムライブラリも開発中とのことだ。テストベッドとしてのプラットフォームが近々公開される運びとなる。
さらに国際標準化活動も始まっている。ISO/IEC JTC 1/SC 42(人工知能関係の分科会)を有力なターゲットとして働きかけ、2023年をめどに活動をしていくとのことだ。第1版の英語版も近々公開されるとのことで、海外の反応にも注目したいところだ。
なお、今回のガイドラインは機械学習に特化したものであり、AIシステム全体の品質管理や運用、組織論などに踏み込んだものではない。不足部分を補う資料としては、一般的なシステム品質に関してはISO/IEC 25000シリーズ(ソフトウェア品質標準)や、ISO/IEC 15408(セキュリティ標準)などがある。AIシステムに関しては、AIプロダクト品質保証コンソーシアムによる「AIプロダクト品質保証ガイドライン2019.05版」が技術的な面でよくまとめられている。さらに、経済産業省の「AI・データの利用に関する契約ガイドライン」は事業者間の契約に関する留意点をチェックするのに有益だ。他にも同省にはAIシステムに関する参考資料がたくさんあるため、関心のある方は一読してみてはいかがだろうか。
関連記事
 大衆化とは違う “AIの民主化”の本質
大衆化とは違う “AIの民主化”の本質
第4次産業革命のキーテクノロジーの1つとされるAI(人工知能)。実装に必要な技術の多くがオープンソースで公開されており、多様なサービスに組み込まれるようになった。意識せずにAIを活用する“AIの民主化”が広がる状況だ。本稿ではAIの民主化の現状を概観し、AI活用の課題や企業が活用するための勘所について考えていく。 AI導入は苦悩の連続、パーソルは3つの壁にどう立ち向かったのか
AI導入は苦悩の連続、パーソルは3つの壁にどう立ち向かったのか
パーソルテクノロジースタッフは、求人ニーズと求職ニーズをマッチングさせる業務の効率化を図ろうと、AI(人工知能)を活用したシステムの開発に着手した。しかし、その道のりは苦難の連続だった。 AIがPoCで止まる――費用は100分の1、PoCは15分、嘆きから生まれたAI分析ツールとは
AIがPoCで止まる――費用は100分の1、PoCは15分、嘆きから生まれたAI分析ツールとは
「AI導入は数億単位の費用がかかる」「ツールが難しい」「長期のPoCで取り組みが止まる」――こうした常識を覆し、費用は通常の100分の1程度、現場ユーザーでも活用でき、1回のPoCを15分にまで短縮したAIの分析ツールがある。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- タダで使える国会図書館の文字起こしツール、汚い手書き文字で精度をガチ検証
- Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
- Geminiで「AIを使いたい現場」と「ダメと言う会社」のギャップを埋める方法
- 舞鶴市「脱Windows」で6億円削減 1人1日82分を時短したGoogleツールの使い方
- 2027年、IT資格はこう変わる 新試験の変更ポイントと未経験からの受験体験記
- デジタル庁、生成AIの利用実績を初公表、職員の間で利用格差も
- PPAPをやめた後、何が起きた? メール対策調査で見えた企業の迷い
- 青梅市役所「そのままDX」の導入部署を拡大 帳票そのままデジタル化を実現
- 「コードを全部消せ」 Java向けテストツールに仕込まれた隠し命令がヤバい:884th Lap
- 定番データベースを捨て、あのコーディングAIにエンジニアたちが群がる理由
アイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。