匿名化ソリューションとは? 導入方法、代表的なソリューションを整理する:IT導入完全ガイド(2/3 ページ)
データ匿名化ソリューションの選定ポイント
こうしてデータ匿名化の方針が決まったとして、ではそれを実行するために利用する技術やツールは、どのような指針の下選択すればいいのだろうか。ごく単純な匿名化処理であれば、データベースソフトウェアや開発ツールにオプション機能として付随しているツールでも事足りるかもしれない。
しかしこうしたツールは、ソフトウェア開発の現場で本番データベースを匿名化してテストで利用するような用途を前提としており、パーソナルデータの幅広い利活用のための本格的な匿名化には力不足であることが多い。
そこで導入を検討したいのが、k-匿名化による高度なデータ匿名化を可能にする専用ツールだ。既に何社かのベンダーからこうした製品が提供されており、徐々に導入事例も出てきている。
処理性能に関する考え方
k-匿名化のアルゴリズムは、既に10年以上に渡る研究の実績があり、ある程度成熟の段階に達している。そのため、どのツールを選んでもデータを匿名化した結果に大きな差が生じることはないだろう。一方、実際にk-匿名化の技術をシステムに落とし込んで実装するに当たっては、ベンダーごとに目指す方向性や打ち出す技術などの違いが表れている。
例えば、処理性能。k-匿名化は多くの演算処理を必要とするため、それを実行するコンピュータにも高い処理負荷が掛かる。そのため、k-匿名化の研究と実用化の取り組みにおいても、処理負荷をいかに低減するかが常に重要なテーマだった。この課題に対しては、大きく分けて2つのアプローチ方法がある。
1つは、とにかく高性能な処理基盤を採用して、どれだけ大規模なパーソナルデータであっても短時間で処理できることを目指すというもの。例えばHadoopの多ノード構成を採用し、大量のパーソナルデータを一気に並列処理できるような製品がこれに当たる。
一方で、小規模な自治体や法人などで大規模なIT投資が難しい組織であっても、限られたコンピューティングリソースで効率的にk-匿名化を実現することを重視した製品もある。ある程度までの規模のデータであれば、デスクトップPCでもk-匿名化を短時間で実行できるよう、効率的な処理方式を備えることを売りにしている製品もある。
自社で取り扱うパーソナルデータの規模や、処理時間に関する要件、さらには用意できる予算やリソースなども加味しながら、自社に適切な処理性能を持った製品を選ぶべきだろう。
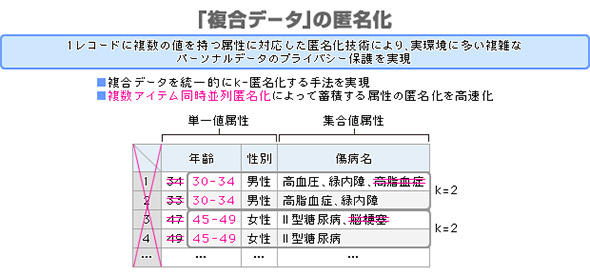 図1 処理負荷を減らす工夫 (出典:NECソリューションイノベータ)
図1 処理負荷を減らす工夫 (出典:NECソリューションイノベータ)どのようなレコードに対して匿名化を行うかによって、必要な処理と負荷が変わるため、手法によっては軽量化できる
※単一値属性:年齢や性別のように1レコードに単一の値を持つ属性
集合値属性:傷病名のように1レコードに複数の値を持つ属性
複合データ:単一値属性と集合値属性の組み合わせからなるデータ
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- タダで使える国会図書館の文字起こしツール、汚い手書き文字で精度をガチ検証
- Excelの10万行データを3分でAIに処理させる、M365 Copilotの使い方
- 「前任者が不在」でも大丈夫 PCログからAIがマニュアルを自動作成する時代へ
- Geminiで「AIを使いたい現場」と「ダメと言う会社」のギャップを埋める方法
- 「RPAの二の舞」はもうゴメン……AIエージェントにささやかれる不吉な予感って?
- 中小企業の採用から勤怠・経費管理まで バラバラのSaaSからまとめてAIがデータ分析
- AIで人は幸せになれるのか? 「AIで稼ぐ企業」と「コストを負担する企業」
- 舞鶴市「脱Windows」で6億円削減 1人1日82分を時短したGoogleツールの使い方
- 2027年、IT資格はこう変わる 新試験の変更ポイントと未経験からの受験体験記
- 手作業で消耗する人とそうでない人の差 全員がAIを「当たり前に使う職場」の作り方
アイティメディアからのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。